Docker 教程记录
Docker
docker top db
PID: Process ID;PPID: Parent Process ID。
pgrep <program>
获取 program 进程号。
cat /proc/$PID/environ
# 一样
docker exec -it <program> env
Namespaces(命名空间)
命名空间限制了进程可以看到以及可以访问系统的特定部分(其他网络接口以及进程)。
当容器启动,container runtime e.g. Docker,会创建新的 命名空间 来沙箱进程。
进程跑在自己 Pid namespace,就像系统上只有这一个进程一样。
- Mount (mnt)
- Process ID (pid)
- Network (net)
- Interprocess Communication (ipc)
- UTS (hostnames)
- User ID (user)
- Control group (cgroup)
创建命名空间:
clone()创建新线程和进程;新进程能复用 none/all/some 其父命名空间。
- 在 shell 中
unshare()。
访问命名空间:setns()。
声明周期:
- 命名空间最后一个进程退出,命名空间销毁;
- 移除所有相关资源。
ll /proc/<self pid>/ns
UTS namespace
- UTS= UNIX time sharing;
- gethostname/sethostname;
- 为
container设置自定义hostname; - 设置
NIS domain。
Net namespace
- 每个有自己私有的网络栈;
- 网络接口(包括
lo); - 路由表;
iptables链和规则;- sockets(通过
ss,netstat查看)。
- 网络接口(包括
- 每个创建一个
veth pair;- 一个
veth在容器网络命名空间,重命名为eth0; - 另一个
veth在主机的host,例如docker0bridge。
- 一个
Mnt namespace
- 进程有自己的
root fs(chroot); - 拥有私有的
mounts;- 隔离
/tmp /proc,/sys- mount 远程文件系统或敏感数据,只有允许的进程能见到。
- 隔离
PID namespace
- 在一个
PID namespace下的进程只能见同namespace下的进程; - 每个
PID namespace都从 1 开始; PID1的挂了,真个命名空间被杀;- 可以折叠;
ps可以看到其他,但是不能杀。
# 能 ps 到其他
sudo unshare --pid --fork
# mount /proc unshare mount namespace
sudo unshare --pid --fork --mount-proc
IPC
User
Chroot
- 容器进程的最重要的部分是独立于
host的不同文件; - 给进程提供了相对于宿主
OS不同的root目录,这允许了 上面的1;
CGroup(Control Groups)
- 限制了进程能
consume的资源量;/proc目录下,映射到/sysfs/cgroup/目录;- memory
- CPU
- block I/O
- 所有
docker内存在:/sys/fs/cgroup/memory/docker/; - 聚合进程干:
- freezer(SIGSTOP/SIGCONT)
- perf_event(收集多核性能事件)
- cpuset(指定到哪些核运行)
- pids cgroup限制组内的进程数量;
- devices cgroup限制设备节点。
限制内存使用
修改
echo 8000000 > /sys/fs/cgroup/memory/docker/$DBID/memory.limit_in_bytes
查看
docker stats db --no-stream
Memory cgroup
ACCOUNTING:
- 跟踪使用的页:
- file
- anonymous(stack, heap, anonymous mmap)
- active
- inactive
- 每个页都归于一组;
- 每个页可在多组中共享;
cat /sys/fs/cgroup/memory/memory.stat
limits: 用于:物理、内核、所有(包括交换)。
不能超过硬限制:
- 一组线程超过硬限制,内核无法回收内存;
- 触发 OOM killer,进程被杀知道再次低于限制。
对于数据库等状态系统,不能杀进程,得用
oom-notifier。 同样是超过限制:
cgroup中的所有进程冻结,通知发给了用户空间;- 用户空间可以
raise limits,migrate containers等;- 低于限制才解冻。
Cpuset cgroup
- pin 组到指定的
cpu; - 为特定应用保留
cpu; - 减少缓存刷新导致的性能损失;
NUMA系统。
Contiainer
image
container image 是
- 包含了
tar files的tar file; files+metadata;- metadata:
- author;
- 启动的
command; - 设置的
environment variables等;
- metadata:
- 这些文件组成了我们容器的
root filesystem; - 由
layers组成,概念上堆叠起来; - 每个
layer可增加、删除、修改file和metadata; - 共享
layer优化磁盘使用、传输时间以及内存使用。
docker save image > image.tar
busy-box 安装。
空 image
tar cv --files-from /dev/null | docker import - empty
空 image 叫 scratch,允许从 scratch 上构建。
使用 docker import 加载 tarball 到 docker。
docker commit
保存 container 的所有变化到新的 layer,创建新的 image。
docker build
优先用这种。
low 方式:
docker run -it ubuntu
# in ubuntu
apt-get update && apt-get install figlet
# out ubuntu
docker diff <ubuntu container id|name>
docker commit <ubuntu container id|name> <newImageId>
docker tag <newImageId> figlet
image namespace
- 官方镜像 e.g.
ubuntu; - 用户或组织镜像 e.g.
jpetazzo/clock; - 自供
docker.elastic.co/elasticsearch/elasticsearch:7.9.1-arm64
layer
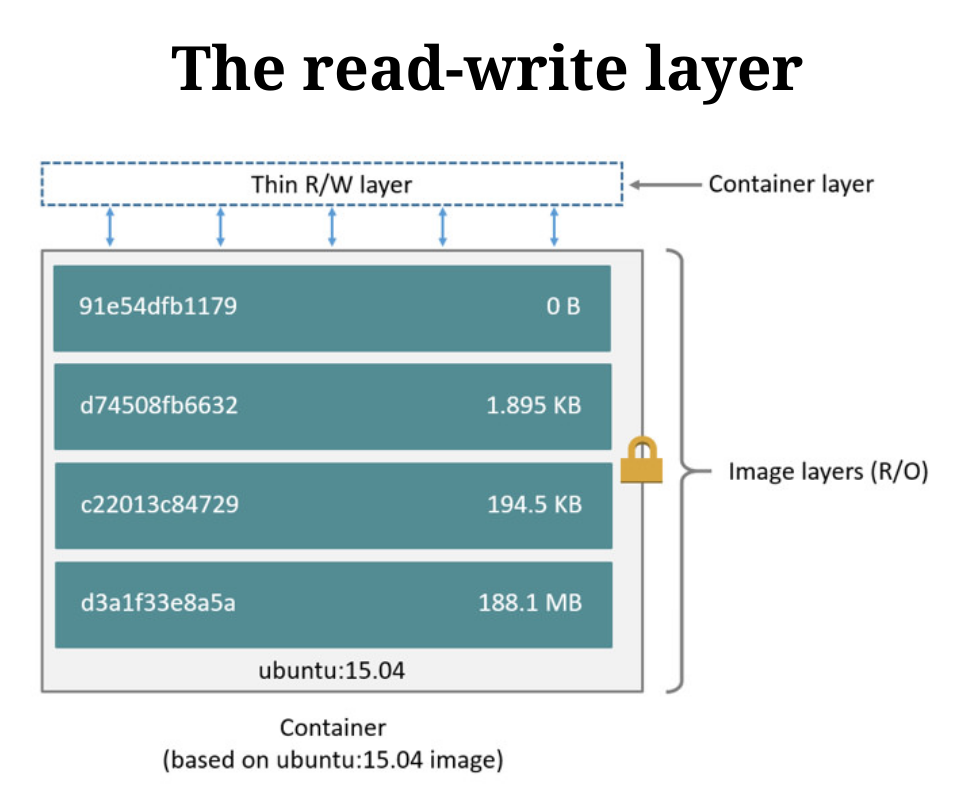
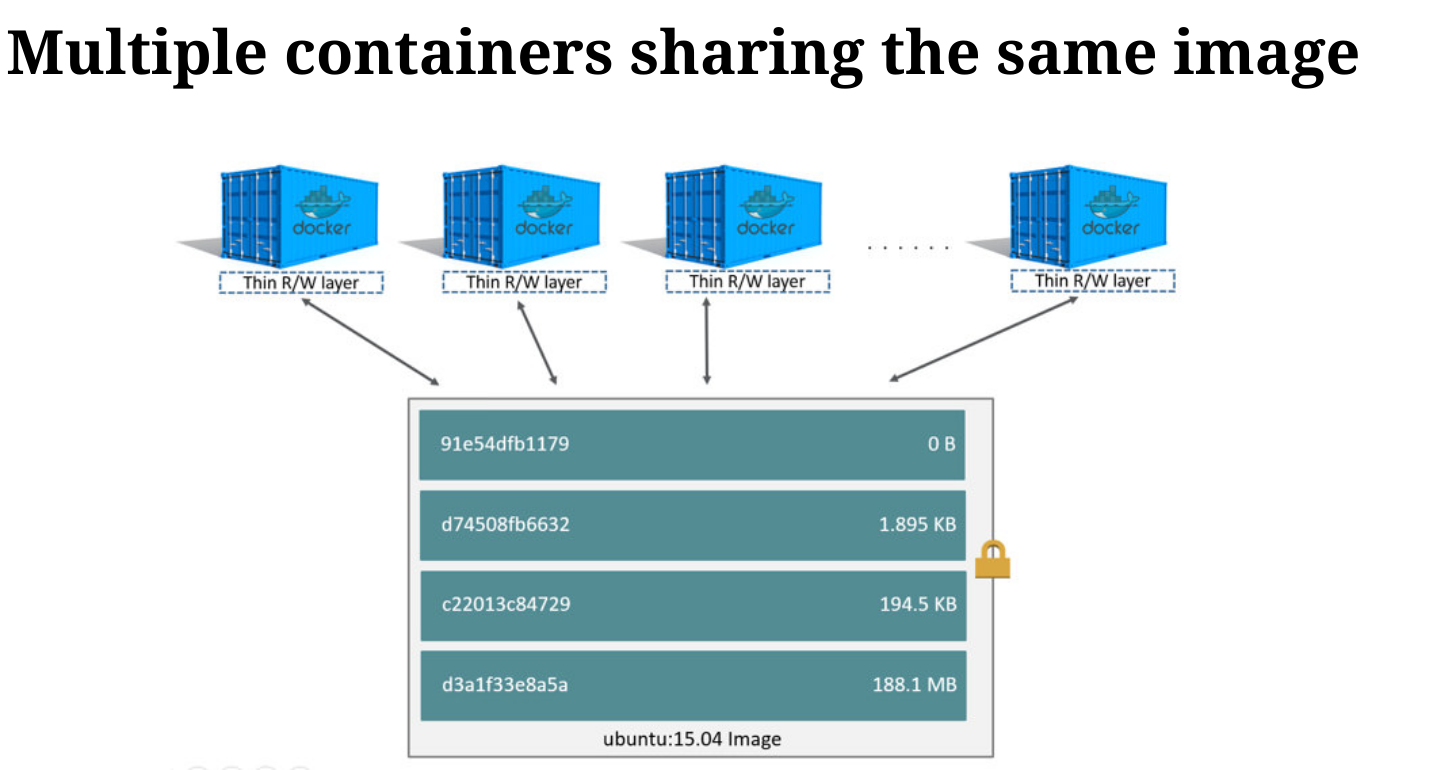
containers vs. images
image: 只读文件系统;container: 封装的一系列进程;跑在上面的只读文件系统的副本中;- 使用了
copy-on-write代替普通的copy。
部署第一个 container
docker run -d image
查看
# 所有
docker ps
# 查看详情
docker insepct <container-id>
# 查看日志
docker logs <container-id>
停止
# 立即杀死
docker kill <container id|name> ...
# 发 TREM 信号, 10s 后发 KILL
docker stop <container id|name>
端口映射
# 6379 到随机端口
docker run -d --name redisDynamic -p 6379 redis:latest
# 查看映射出来的端口
docker port redisDynamic 6379
目录映射
docker run -d --name redisMapped -v <host-dir>:<contiainer-dir> redis
# e.g.
docker run -d --name redisMapped -v /opt/docker/data/redis:/data redis
前台跑
# 跑 ubuntu 并且执行 ps 命令
docker run ubuntu ps
# 进入容器访问 bash shell
docker run -it ubuntu bash
# -i: 我们与容器 stdin 连接
# -t: 我们想要一个 psedo-terminal(伪终端)
name &
# 启动时指定名字
docker run --name
# 改名
docker rename
编写第一个 Dockerfile
FROM nginx:alpine
COPY . /usr/share/nginx/html
docker build -t webserver-image:v1 .
docker run -d -p 80:80 webserver-image:v1
# 比上面多启动 nginx
FROM nginx:1.11-alpine
COPY index.html /usr/share/nginx/html/index.hml
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]
CMD & ENTRYPOINT
UNIX 中开始新的程序:
fork()创建子进程;execve()替换新的子进程运行。execve(program, [list, of, arguments]);sh -c就是用shell来分割命令参数。
# 这里还是用 sh,但是 figlet PID = 1
# figlet 开始时,sh 被替换
CMD exec figlet -f script hello
CMD定义了一个默认执行的指令(如果没有的话);- 能在文件的任何位置;
- 后面的
CMD会替换前面的;多条没有用。
FROM ubuntu
RUN apt-get update
RUN ["apt-get", "install", "figlet"]
# 定义了 base 指令以及参数
# 命令行参数加在这些后面
ENTRYPOINT ["figlet", "-f", "script"]
执行下面命令:
docker run figlet salut
# 等同于
sh -c "figlet -f script" salut
CMD + ENTRYPOINT:
ENTRYPOINT ["figlet", "-f", "script"]
# 当命令行没有参数,CMD 添加在后面,否则被替代
CMD ["hello world"]
node.js
FROM node:10-alpine
RUN mkdir -p /src/app
WORKDIR /src/app
COPY package.json /src/app/package.json
RUN npm install
COPY . /src/app
EXPOSE 3000
CMD ["npm", "start"]
# -e 设置环境变量
docker run -d --name my-production-running-app -e NODE_ENV=production -p 3000:3000 my-nodejs-app
OnBuild
ignore file
.dockerignore 文件放入不打进容器的文件列表。
Data Container
唯一用于 存放、管理数据。
# 创建一个 data container
docker create -v /config --name dataContainer busybox
# 复制到 data container 中
docker cp config.conf dataContainer:/config/
# --volumes-from
docker run --volumes-from dataContainer ubuntu ls /config
导入、导出 data container
docker export dataContainer > dataContainer.tar
docker import dataContainer.tar
link 连接网络
--link <container-name|id>:<alias>
做两件事:
- 基于连接的容器设置环境变量,可以通过名字来引用端口、IP 等信息;
- 更新
HOSTS文件
修改 environment variables
# e.g. alpine env 命令会输出所有 environment variables
docker run --link redis-server:redis alpine env
输出:
REDIS_PORT=tcp://172.18.0.2:6379
REDIS_PORT_6379_TCP=tcp://172.18.0.2:6379
REDIS_PORT_6379_TCP_ADDR=172.18.0.2
REDIS_PORT_6379_TCP_PORT=6379
REDIS_PORT_6379_TCP_PROTO=tcp
REDIS_NAME=/elastic_sammet/redis
REDIS_ENV_GOSU_VERSION=1.10
REDIS_ENV_REDIS_VERSION=4.0.11
REDIS_ENV_REDIS_DOWNLOAD_URL=http://download.redis.io/releases/redis-4.0.11.tar.gz
REDIS_ENV_REDIS_DOWNLOAD_SHA=fc53e73ae7586bcdacb4b63875d1ff04f68c5474c1ddeda78f00e5ae2eed1bbb
修改 hosts
# alias 原始名称 hash-id
172.18.0.2 redis bac813a4509b redis-server
Networks
publish all
# exposed port -> 随机端口
docker run -d -P nginx
# 查看镜像 exposed port
docker inspect --format '' nginx
# 查看映射的端口
docker port <container id> <exposed port>
# 查看 container ip
docker inspect --format '' <yourContainerID>
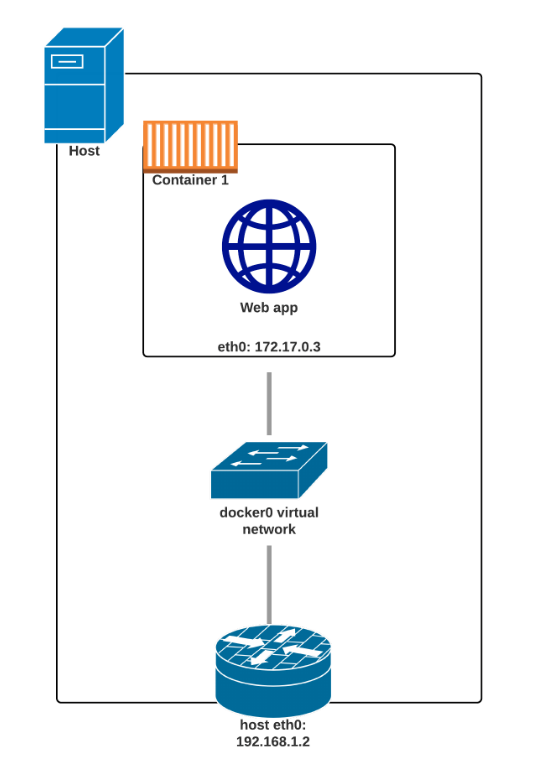
network driver
- bridge(default)
- none
- host
- container
default bridge
- 容器默认获得一个虚拟
eth0;- 除了自己的
loloopback interface
- 除了自己的
eth0通过veth pair(virtual Ethernet devices) 提供;- 连接两个
network namespace的方法。
- 连接两个
- 另一端连接到
Docker Bridge; ip地址是私有、内部的子集;- 默认
172.17.0.0/16,通过--bip配置;
- 默认
- 出口流量走
iptables MASQUERADE规则; - 入口流量走
iptables DNAT规则; - 容器有自己的路由、
iptables规则。
null driver
# 只有 lo,没有 eth0,对于独立或不可靠
docker run --net none
host driver
# 看到和访问 host 的网络接口
# 绑定任何地址和接口,流量不走 NAT,bridge, veth
# 对于性能高敏
docker run --net host
container driver
# 复用其他 container 的网络栈
# 共享 接口,ip,路由,iptables
# 通过 lo 交流
docker run --net <container:id>
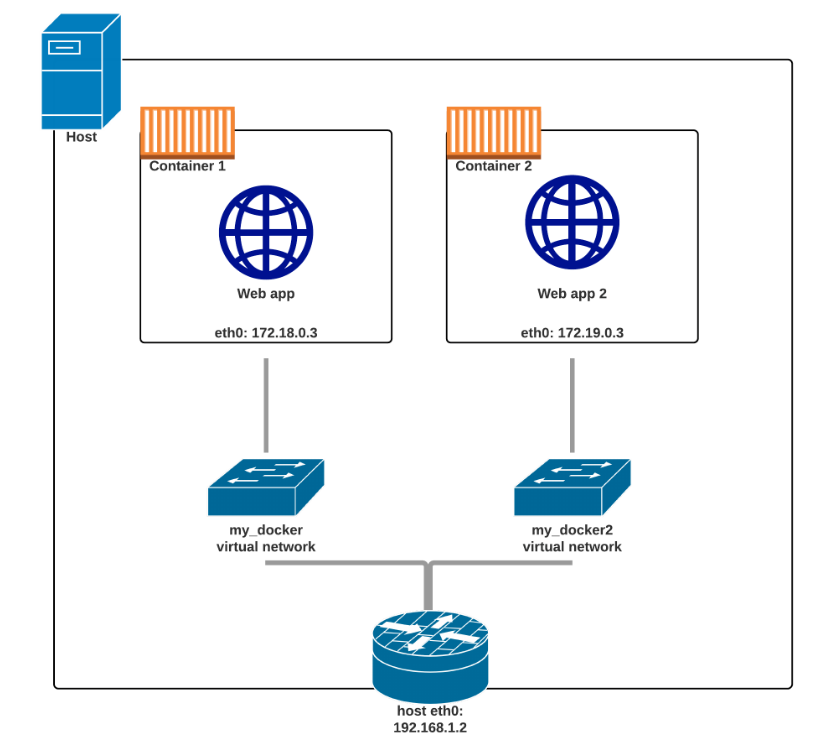
network
# 创建 network
docker network create backend-network
# 容器使用 network
docker run -d --name=redis --net=backend-network redis
- 环境变量和
HOSTS都不会增加其他容器的信息; - 使用
Docker内置DNS,resolv.conf中nameserver设置为127.0.0.11。
# 查看所有网络
docker network ls
# 查看某网络详情
docker network inspect frontend-network
# 网络断连
docker network disconnect frontend-network redis
或者使用
# 创建网络
docker network create frontend-network
# connect 已有的容器到网络
docker network connect frontend-network redis
多container 在一个网络
docker network create dev
# 创建 es 指定网络
docker run -d --name es --net dev elasticsearch:2
# 可以 ping 通 es
docker run -ti --net dev alpine ping es
相同 image 多个 container
docker network create prod
# 创建两个 es 在网络,alias 同一名称
docker run -d --name prod-es-1 --net-alias es --net prod elasticsearch:2
docker run -d --name prod-es-2 --net-alias es --net prod elasticsearch:2
# nslookup 会返回两条记录,round robin
docker run --net prod --rm alpine nslookup es
# output
# Server: 127.0.0.11
# Address: 127.0.0.11:53
# Name: es
# Address: 172.22.0.3
# Address: 172.22.0.2
docker-compose自动创建网络和网络别名。
round robin不可靠,不要作为负载,而且新的节点需要重新resolve。
由于一个
container可能加入多个网络,可能es在多个网络中有不同 IP,可以使用es.dev和es.prod区分。
container network 原理
# 创建一个有自己 net ns 的进程
sudo unshare --net
# 在新进程中,无法 ping 通
ping 1.1
# 同样在这里,只有一个 lo
ip link ls
# 在 host,创建 veth pair
sudo ip link add name in_host type veth peer name in_netns
# 同样,设置 host side(in_host)
sudo ip link set in_host master docker0 up
# 在新进程中,检查 PID
echo $$
# 在 host 中,将另一端(in_netns) 到新进程中
sudo ip link set in_netns netns <PID>
# 在新进程中
ip link set lo up
# 启动 veth 并且重命名为 eth0
ip link set in_netns name eth0 up
# 在 host 中查看 docker bridge
ip addr ls dev docker0
# output like:
# 6: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
# link/ether 02:42:58:e0:aa:9d brd ff:ff:ff:ff:ff:ff
# inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
# valid_lft forever preferred_lft forever
# inet6 fe80::42:58ff:fee0:aa9d/64 scope link
# valid_lft forever preferred_lft forever
# 在新进程中,设置 ip 以及默认路由
ip addr add 172.17.0.99/24 dev eth0
ip route add default via 172.17.0.1
# 接着就能 ping 通
ping 1.1
Volumes
为了共享数据将宿主机的目录映射到容器。双向的。
VOLUME /uploads
或
docker run -d -v /uploads myapp
或
# ro: read only
docker run --volues-from <container-name|id>
特性:
volumes不是在host和container间复制和同步;- 是
bind mounts,类似于符号链接,但在不同级别; - 修改文件实时可见,是同一文件。
用于:
- 绕过
copy-on-write:- 获取原生硬盘
I/O性能; - leave some files out of
docker commit。
- 获取原生硬盘
- 多容器间共享文件夹;
- 主机和容器间共享文件夹、单个文件;
- 远程存储;
- 不能用于
k8s,swarm。
使用 –mount
Log Files
容器启动,Docker 会跟踪标准输出和标准错误。
docker logs <container-name|id>
默认以 json 文件 存储。可替换为:
- Syslog:写入主机的
central syslog - None: 关闭
docker run --log-driver=syslog <container>
日志设置
# max-size 可以日志滚动
# max-file 限制文件数量
docker run --log-opt max-size=10m --log-opt max-file=3 elasticsearch
插件:
- json-file
- Syslog
- journald
- gelf
- fluentd
- splunk
资源限制
RAM
如果进程用了太多的内存。
- 如果有
swap使用之; - 没有足够的
swap空间,调用OOM killer; OOM killer尝试杀进程;- 可能杀无关进程。
cgroup 只杀超过限制的 container。
# 物理 RAM
# 超过 100MB,如果 swap 能用,不会被杀
docker run --memory 100m python
# 总 RAM(RAM + swap)
docker run --memory 100m --memory-swap 100m python
CPU
--cpu-shares 1024,相对优先级;--cpus 0.110%,--cpus 1010 个 CPU;--cpuset-cpus 3,5,7,使用 3,5,7 号 cpu。
Disk
重启策略
Docker 认为任何以非 0 状态退出都是 crash,默认 crash container 保持停止。
# 有限次数重启
docker run --restart-on-failure:<num> <container>
# 一直重启
docker run --restart=always <container>
元数据和标签
推荐格式:
- 使用
reverse DNS方式:io.github.gh0st99; - 小写;
- [a-z0-9-.]
用途:
- vhost
- backup schedule
- ownership
# 加一个标签
docker -l key=value
# 从文件加入
docker -label-file=<label file path>
通过标签过滤 container
# 过滤包含特殊标签
docker ps --filter lable=key
# 过滤包含特殊值的特殊标签
docker ps --filter label=key=value
docker images --filter label=key=values
给 docker 加标签
docker -d \
-H unix:///var/run/docker.sock \
--label com.katacoda.environment="production" \
--label com.katacoda.storage="ssd"
LABEL vendor=Gh0st99
LABEL io.github.gh0st99.version=0.0.1\io.github.gh0st99.build-date=2020-09-15:09:29:46z
负载均衡容器
容器互相交流有两种方式:
- 修改
environment variables和hosts文件; - 使用
Service Discovery模式。- 使用三方系统识别目标系统的位置。
Nginx Proxy
docker compose
docker stats
# 单一
docker stats <container name|id>
# 所有运行
docker ps -q | xargs docker stats
docker multi-stage builds
# 第一阶段, 准备 Go 环境,编译 binary
FROM golang:1.6-alpine
RUN mkdir /app
ADD . /app/
WORKDIR /app
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o main .
# 第二阶段,把第一阶段产物复制过来
FROM alpine
EXPOSE 80
CMD ["/app"]
# 将第一阶段生成的 main 复制到根目录改名 app
COPY --from=0 /app/main /app
# 第一阶段昵称 compiler
FROM ubuntu AS compiler
RUN apt-get update
RUN apt-get install -y build-essential
COPY hello.c /
RUN make hello
FROM ubuntu
# 将第一阶段的 hello 复制到本阶段
COPY --from=compiler /hello /hello
CMD /hello
运行:
docker build -t hellomultistage .
docker run hellomultistage
# 打中间状态的 image
docker build --stage compiler --tag hellocompiled
Dockerfile每一行创建一个新layer;- 联合
&&以及\。
优化 dockerfile
善用 COPY
FROM python
# 这里使用 COPY 创建 layer,能更有效缓存
COPY requirements.txt /tmp/requirements.txt
# 只有 requirements.txt 变时才 install
RUN pip install -qr /tmp/requirements.txt
WORKDIR /src
COPY . .
EXPOSE 5000
CMD ["python", "app.py"]
chown,chomd,mv 要小心
- layers 无法有效的存储权限和所有者的改变;
- 对于
mv也一样; - 所以这些指令在
RUN之后都会拷贝整个文件。
COPY some-file .
# 拷贝 some-file
RUN chown www-data:www-data some-file
# 拷贝 some-file
RUN chmod 644 some-file
# 拷贝 some-file
RUN mv some-file /var/www
解决之道:
- 使用一个
layer解决; - 使用
COPY --chown=user:group src dest;user必须在/etc/passwd或/etc/group中。
- 在本地设置好文件权限,
COPY会保留。
美化输出
docker ps --format ' container is using image'
docker ps -q | xargs docker inspect --format ' - - '
容器进程 vs. 主机进程
- 两者每个线程都属于
namespaces&cgroups;- 属于上面的俩决定进程的所见和所做;
- 以特定的
UID运行;- UID = 0, root
分析 container
# 查看异常退出的 container
docker ps
# 方法 1.
## 查看变更的文件
docker diff <container id>
## 复制出来日志等有用文件查看
docker cp <container id>:/var/log/error.log .
# 方法 2.
## 创建新的镜像
docker commit <container id> debugimage
## 自定义入口
docker run -ti --entrypoint sh debugimage
## 生成 tar 文件,并查看里面的内容
docker export <container id> | tar tv
init system
init system: PID 1。
- 创建其他进程;
- 获得孤立的僵尸进程。
- 进程退出时,变僵尸(
top中标记为Z); - 其父进程必须
reap僵尸进程。调用waitpid()获取退出状态; - 如果进程退出,其子进程成为孤儿;
- 这些孤儿进程
re-parent到PID 1。
- 进程退出时,变僵尸(
应用以
PID 1跑。
Docker 自动提供一个 init(tinit) 进程:
- 获取僵尸进程;
- 转发信号;
- 当子进程退出,
tinit退出。
docker run jpetazzo/hamba 80 www1:80 www2:80
其 dockerfile 为:
FROM alpine
RUN apk update && apk add haproxy
ADD hamba /usr/local/bin/hamba
ENV HOME /run
VOLUME /run
ENTRYPOINT ["hamba"]
这里 entrypoint 干了:
- 解析参数;
- 生成配置文件;
- 启动实际服务。
安全
capabilities;- 容器默认关闭所有危险的;
- 通过
docker run --cap-add添加;
seccomp: secure computing。容器搞定,不用操心;security modules:SELinux(Red Hat);AppArmor(AppArmor).LSM给所有进程操作加了一层访问控制;- 容器搞定,不用操心。
copy-on-system
- 允许共享数据的机制;
- 出现的数据是一份拷贝,但只是链接到原来的数据;
- 当改变共享数据时才实际复制;
AUFS
- 按照特殊顺序合并多个分支;
- 每个分支只是一个普通文件夹;
- 至少一个只读分支(最底部);
- 只有一个读写分支(最顶部)。
打开文件:
O_RDONLY:- 从顶上开始每个分支找;
- 打开第一个找到的。
OWRONLY或O_RDWR:- 如果在顶上,打开之;
- 如果在其他分支,复制到顶上;
- 如果不存在,在顶上创建。
性能:
mount()快,所以创建容器快;- 读写拥有原生性能;
open()两种情况性能昂贵:- 写大文件(日志、数据库);
- 在许多层上搜索许多文件夹;
- 当同一容器启动多次:
- 磁盘上的数据只加载一次,在内存中只缓存一次;
dentries会重复。
Overlay2
- 比
AUFS简单,只能有两层; - 在层间使用硬连接,提高
open()&stat()性能。
Docker 引擎组成
- dockerd
- containerd
- containerd-shim
- runc
Swarm 教程
基本概念
- cluster
- node
- manager: 对其进行
api调用,只有一个是leader,其他的将请求转给leader。 - worker: 从
manager那获得指令。
- manager: 对其进行
- service:
leader使用不同子系统将service分解城task。- task:与特殊的
container对应,被分配个一个特殊的node。
- task:与特殊的
- node
启动
在 swarm 模式下,每个 node 将自己的 ip 宣告给其他 node。
# 控制用
--advertise-addr eth0:7777
--listen-addr eth0:7777
# 数据用
--data-path-addr
task 的声明周期:
assigned: 已经被分配个一个node;preparing: 拉取镜像;startingrunning
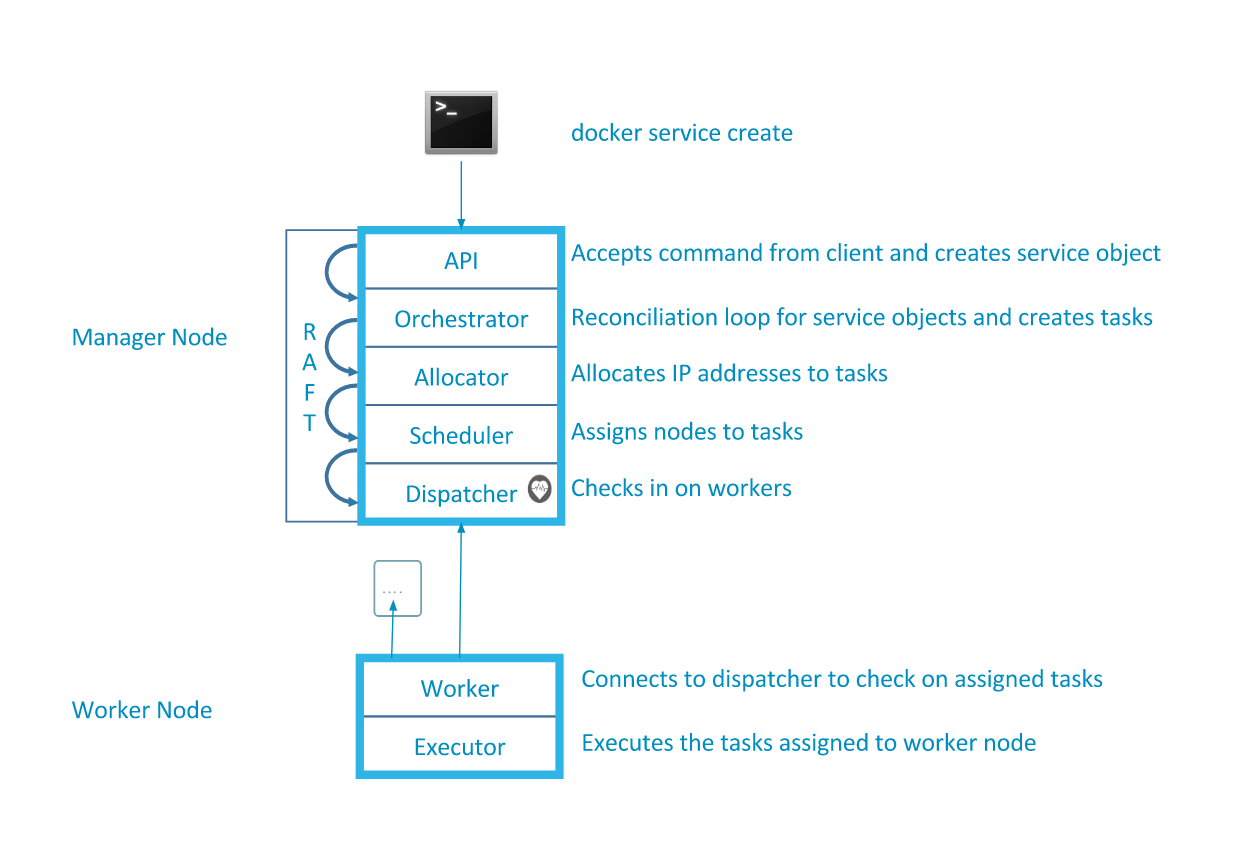
manager 的容错性
2N + 1 可以容忍 N 失败。
不能使所有节点都成 manager。
Raft将写都发给所有的节点;- 数量众多的群体很难达成一致;
- 每个节点 ping
Manager< 10ms。
最佳规范,节点数:
- 3 - 5:所有都是
manager; - 5 - 10: 剩下都是
worker; - 10 - 100:5 个最稳定的做
manager; - > 100:
manager得 4C, 16G, SSD。
K8S 教程
部署应用
kubectl create deployment kubernetes-bootcamp --image=gcr.io/google-samples/kubernetes-bootcamp:v1
创建一个 deployment:
- 找一个应用实例能运行的合适的节点;
- scheduled 应用使其在那个
Node上跑; - 配置集群当需要的时候将实例编排到新
Node上。
K8S 中跑的 Pods 跑在 私有隔离的网络上。
- 默认对同
K8S 集群上其他Pods和services可见; - 这个网络外的不可见。
kubectl proxy
会创建一个 terminal 到 K8S 集群 的连接。终端可以直连到 API。
通过 proxy endpoint 可以看见这些 APIs。e.g.
curl http://localhost:8001/version
API Server 基于 pod name 自动为每个 Pod 创建一个 endpoint。
查看 pod 和工作节点
Pod:表示一组一个或多个应用程序容器,以及这些容器的一些共享资源:
- 共享存储,当作卷;
- 网络,作为唯一的集群 IP 地址;
- 有关每个容器如何运行的信息(e.g. port, version)。
Pod:
- 逻辑主机;
- 共享
IP & Port; - 平台原子单元;
- 创建
Deployment,会在其中创建包含容器的Pod;- 每个
Pod与调度它的工作节点绑定直到,直到终止; - 如果
Node出现问题,则在其他可用Node调度相同的Pod。
- 每个
工作节点:
主节点管理工作节点,工作节点有多个 Pod。
主节点自动处理集群中工作节点调度 pod。
pod中的容器共享一个网络空间;docker fun --net=container:<container_id>
- 有一个特殊
sandbox容器; - 使用
k8s.gcr.io/pause共享网络; pod中的容器有独立的文件系统,通过volumes共享文件夹;