ES 教程记录
ES
入门操作
集群创建索引
3 节点的 ES 集群。
创建 3 分片,1 副本的索引。
curl --request PUT \
--url http://localhost:9200/blogs \
--header 'content-type: application/json' \
--data '{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}'
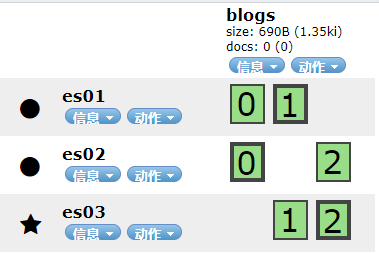
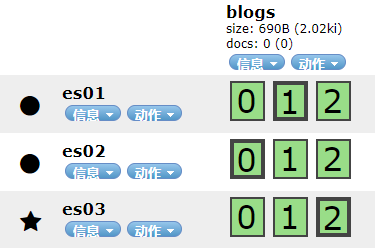
然后更新副本数量为 3。
curl --request PUT \
--url http://localhost:9200/blogs/_settings \
--header 'content-type: application/json' \
--data '{
"number_of_replicas" : 2
}'
自动生成的 ID 为 Base64 最多 20 个字符的 GUID 字符串。
文档不可变,不能修改它们。使用相同的 API 进行替换:
_version会变;created也变为false;- 旧文档标记为删除,增加全新的文档。旧文档在后台被处理。\
乐观锁处理冲突
重建文档的索引时通过指定 version 为我们的修改被应用的版本。
- 假如并发修改,一个成功,另一个会收到
409 Conflict的状态码。
bulk 批量加入文档
curl -H "Content-Type: application/json" -XPOST "localhost:9200/<index-name>/_bulk?pretty&refresh" --data-binary "@data.json"
文档数量最好
1000 - 5000, 总大小5MB - 15MB。
basic search
bank 格式如下:
{
"account_number": 568,
"balance": 36628,
"firstname": "Lesa",
"lastname": "Maynard",
"age": 29,
"gender": "F",
"address": "295 Whitty Lane",
"employer": "Coash",
"email": "lesamaynard@coash.com",
"city": "Broadlands",
"state": "VT"
}
查找所有
curl --request GET \
--url http://localhost:9200/bank/_search \
--header 'content-type: application/json' \
--data '{
"query": {
"match_all": {}
},
"sort": [
{ "account_number": "asc" }
],
"from": 10,
"size": 10
}'
- 如果没有
from和size返回的是前 10 条。
返回样例:
{
"took" : 63,
"timed_out" : false,
// 查询的分片以及各种情况
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value": 1000,
"relation": "eq"
},
"max_score" : null,
"hits" : [ {
"_index" : "bank",
"_type" : "_doc",
"_id" : "0",
"sort": [0],
"_score" : null,
"_source" : {"account_number":0,"balance":16623,"firstname":"Bradshaw","lastname":"Mckenzie","age":29,"gender":"F"}
}, {
"_index" : "bank",
"_type" : "_doc",
"_id" : "1",
"sort": [1],
"_score" : null,
"_source" : {"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M"}
} ]
}
}
匹配查询
curl --request GET \
--url http://localhost:9200/bank/_search \
--header 'content-type: application/json' \
--data '{
"query": {
"match": {"address": "mill lane"}
}
}'
- 这样会查询
address包含mill或lane的; - 要精确查包含
mill lane的就要match–>match_phrase。
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
// 不匹配的
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}
- 还有
should;must和should会影响匹配文档的score;must_not当作filter来用,不影响score。
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
聚合
这里按照 stats 聚合,返回 balance 的平均值以及聚合的文档数量并按照 balance 倒序。
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
// state 类型为 text
"field": "state.keyword",
"order": {
"average_balance": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
index 模型
静态设置
index.number_of_shards: 主分片的数量,只能在创建时设置;index.number_of_routing_shards: 分割index的路由分片的数量;
动态设置
mapping
merge
ES 中 shard 是一个 Lucene 索引,Lucene 索引分割成 segments。
segment不可变;segment周期性的合并来除去删除以及保持index大小;ConcurrentMergeScheduler控制合并线程数。
相似性
存储
根据系统选择最佳的存储。
translog
index 排序
curl -X PUT "localhost:9200/my-index-000001?pretty" -H 'Content-Type: application/json' -d'
{
"settings": {
"index": {
"sort.field": [ "username", "date" ],
"sort.order": [ "asc", "desc" ]
}
},
"mappings": {
"properties": {
"username": {
"type": "keyword",
"doc_values": true
},
"date": {
"type": "date"
}
}
}
}
'
- 先按照
username升序,然后按照date降序。 - 可以使连接更有效。
Mapping
创建索引附带 mapping
curl -X PUT "localhost:9200/my-index-000001?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}
'
查看 mapping
curl -X GET "localhost:9200/my-index-000001/_mapping?pretty"
查看字段的 mapping
GET /my-index-000001/_mapping/field/employee-id
字段类型
Array
没有专用的数据类型。都是 Lucence 的成果。
- Lucene tokenizes the text into individual terms;
- 每个
term分别加入到indverted index中。
分布式 Document 存储
shard = hash(routing) % number_of_primary_shards
- routing:
string,默认是_id。
这里解释了为什么 primary shard 的数量只能在 index 创建时被设置而且不能改变。因为如果改变,之前的 routing 都会无效。
下面所有请求发给 Node 1,则其称为 协调节点。
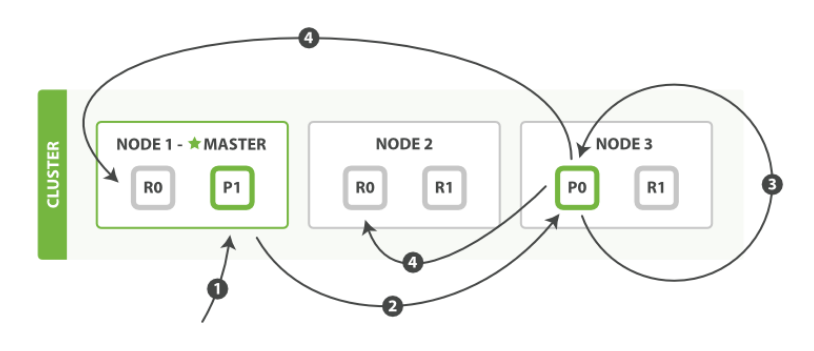
写 Document 到集群
| Node1 - Master | Node2 | Node3 |
|---|---|---|
| R0 P1 | R0 R1 | P0 R1 |
- 发
create或delete到Node1 - 节点通过
_id决定document属于shard0。因此forwardNode3,因为主 shard0在那里。 Node3执行,如果成功并发forwardNode1,Node2。这俩节点返回陈宫,再返回成功给客户端。
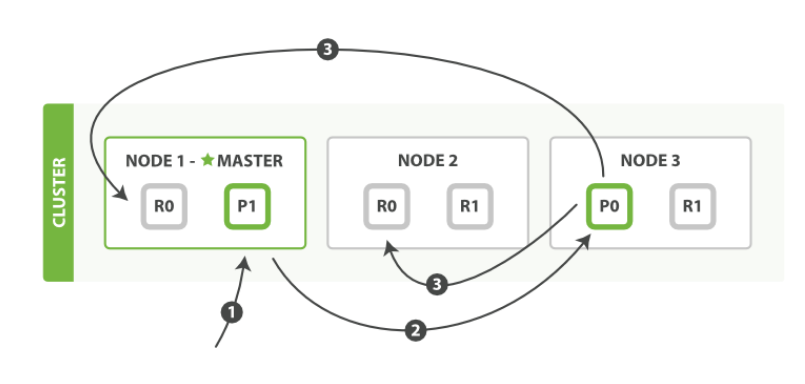
设置:
consistency:- one
- all
- 默认:int( (primary + number_of_replicas) / 2 ) + 1
timeout: 若没有足够的副本,则等待,希望更多的分片出现。默认 60s
数据安全换性能
primary shard 在写操作前需要 quorum 或多分片副本有效。
quorum = int( (primary + number_of_replicas) / 2 ) + 1
- 这样做是为了阻止写数据到
the “wrong side” of a network partition; - 如果有 2 个副本,则
number_of_replicas = 3。
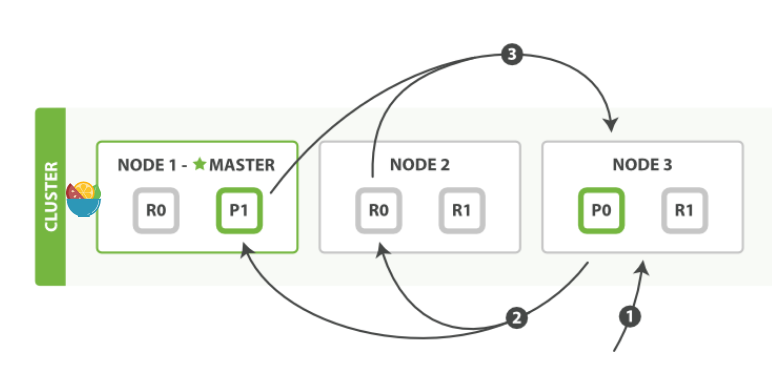
取出 Document
- 发
get到Node1; - 通过计算
_id决定属于shard0。可以走到Node2获取数据; Node2返回给Node1,Node1返回给客户。
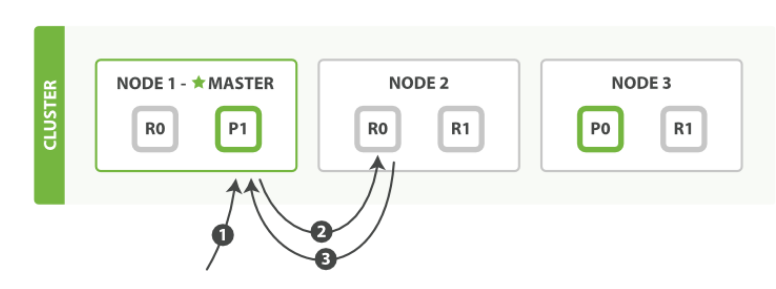
- 在本例中, 协调节点对于每次请求会轮询所有的分片来达到负载均衡**;
- 若副本分片中文档不存在,而住分片存在,则主节点返回。
更新 Document
- 发
update到Node1; - 请求被转给
Node3,因为主分区在Node3; Node3从主分片检索文档,修改_source中的 JSON,尝试重新索引住分片的文档;如果被另一个进程修改,重复直到
retry_on_conflict后放弃。- 如果成功更新,则新版的文档并行转给
Node1和Node2上的副本分片,重建索引。所有副本都返回成功,则Node3返回成功,协调节点湘客户端返回成功。
mget & bulk
本质上是协调节点发给所有包含主分片的节点主机请求。
映射 & 分析
数据可以分为:
- 精确值;
- 全文。
倒排索引
有 2 个文档,content 内容如下:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
| Term | Doc_1 | Doc_2 |
|---|---|---|
| Quick | X | |
| The | X | |
| brown | X | X |
| dog | X | |
| dogs | X | |
| fox | X | |
| foxes | X | |
| in | X | |
| jumped | X | |
| lazy | X | X |
| leap | X | |
| over | X | X |
| quick | X | |
| summer | X | |
| the | X |
创建倒排索引,
- 将
content域拆分为单独的词[条](token); - 创建一个包含所有不重复词条的排序列表;
- 列出词条出现在哪个文档。
如果 normalize 到标准格式:
Quick–>quick;foxes词干提取fox。
| Term | Doc_1 | Doc_2 |
|---|---|---|
| brown | X | X |
| dog | X | X |
| fox | X | X |
| in | X | |
| jump | X | X |
| lazy | X | X |
| over | X | X |
| quick | X | X |
| summer | X | |
| the | X | X |
上述两个步骤分词和标准化称为分析。
分析由分析器执行,分析过程:
- 将一块文本分成适合于倒排索引的独立的词条 ;
- 将这些词条统一化为标准格式以提高它们的“可搜索性”,或者
recall。
分析器包含:
- 字符过滤器(Character filters):分词前整理字符串,清洗;
- 分词器:分为单个词条(token);
- 标准:根据单词边界划分;
- 简单:不是字母的地方分割;
- 空格:在空格处分割;
- 语言:英文、中文。
- Token 过滤器:最后每个
token通过token 过滤器。- 改变词条:
Quick小写; - 删除词条:
a,and,the等无用词; - 增加词条:增加同义词。
- 改变词条:
多值字段 同 full-text 字段一样分析会产生多个 terms。因此多值字段中所有的值都必须是同一种数据类型。 es 会以数组中第一个字段的数据类型作为 type。
多级 objects
对象属性:
{
"gb": {
"tweet": {
"properties": {
"tweet": { "type": "string" },
"user": {
"type": "object",
"properties": {
"id": { "type": "string" },
"gender": { "type": "string" },
"age": { "type": "long" },
"name": {
"type": "object",
"properties": {
"full": { "type": "string" },
"first": { "type": "string" },
"last": { "type": "string" }
}
}
}
}
}
}
}
}
{
"tweet": "Elasticsearch is very flexible",
"user": {
"id": "@johnsmith",
"gender": "male",
"age": 26,
"name": {
"full": "John Smith",
"first": "John",
"last": "Smith"
}
}
}
会被索引为:
{
"tweet": [elasticsearch, flexible, very],
"user.id": [@johnsmith],
"user.gender": [male],
"user.age": [26],
"user.name.full": [john, smith],
"user.name.first": [john],
"user.name.last": [smith]
}
因为:
Lucene不理解内部对象;- 其文档由一些列键值列表组成。
search
query all
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{}
'
等同于
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match_all": {}
}
}
'
条件合并
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{
"bool": {
"must": { "match": { "email": "business opportunity" }},
"should": [
{ "match": { "starred": true }},
{ "bool": {
"must": { "match": { "folder": "inbox" }},
"must_not": { "match": { "spam": true }}
}}
],
"minimum_should_match": 1
}
}
'
查询语言使用情况:
- 过滤(filtering queries);
- 不评分或过滤;
- 简单的查询或排除;
- 可缓存。
- 查询(scoring queries)。
- 找到匹配的文档,计算每个匹配文档的相关性;
- 不可缓存。
组合多查询:
curl -X POST "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool" : {
"must" : {
"term" : { "user.id" : "kimchy" }
},
"filter": {
"term" : { "tags" : "production" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
'
- must: 必须,影响计分;
- filter: 必须,不影响计分;
- 在其下的计分都为 0。
- should: 应该;
- must_not: 必须不。影响计分。
sort
curl -X GET "localhost:9200/my-index-000001/_search?pretty" -H 'Content-Type: application/json' -d'
{
"sort" : [
{ "post_date" : {"order" : "asc"}},
"user",
{ "name" : "desc" },
{ "age" : "desc" },
"_score"
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
'
多字段
相关性
相似读算法:检索词频率/反向文档频率, TF/IDF。
- 词频:检索词在该字段出现的频率;
- 反向文档频率:每个检索词在索引中出现的频率,越高,相关性越低;
- 字段长度:越长,相关性越低。
Doc Values
在匹配文档时倒排索引很快,但是排序不理想。
因为在排序时,我们需要倒排索引中某个字段的集合,转置倒排索引。
转置被称为列存储。
使用场景:
- 字段排序;
- 字段聚合;
- 某些过滤,地理位置;
当数据集 < 可用内存,所有文档在内存,否则在页缓存中。
分布式检索
一个文档的唯一性由 _index + routing values(default _id) 组成。
查询阶段
- 查询广播到索引每个分片拷贝(主 或 副);
- 每个分片本地执行搜索并构建一个优先队列。
e.g.
{
"from": 90,
"size": 10
}
会构建一个能放入 100 条文档的优先队列。
- 客户端发送一个
search请求到Node 3,Node 3会创建一个大小为from + size(这里 100) 的空优先队列; Node 3将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为from + size的本地有序优先队列中;- 每个分片返回各自优先队列中所有文档的
ID和排序值给协调节点,也就是Node 3,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
取回阶段
就是通过 ID 在相应节点找到文档的阶段。
- 协调节点辨别出哪些文档需要被取回并向相关的分片提交多个
GET请求; - 每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点;
- 一旦所有的文档都被取回了,协调节点返回结果给客户端。
上例中,只需要 [91-100] 这 10 条结果。前面 90 个全部抛弃。
注意 深分页。
使用 scroll 来处理深分页。
- 游标查询先做查询初始化,然后批量拉取结果。
- 取某个时间点的快照,之后的变化被忽略。
索引管理
类型和映射
Lucene 没有文档类型,每个文档的类型名存储在 _type 元数据字段上。检索文档时通过 _type 使用过滤器限制返回这个类型的文档。
没有映射,将复杂 JSON 扁平化。
由于 type 已经被废除,下面只用于了解。
每个类型的字段在 Lucene 中只有一个映射。
映射在本质上被 扁平化 成一个单一的、全局的模式。
默认,在 _source 字段存储代表文档体的JSON字符串。
分片内部原理
倒排索引还会存入:
- 每个
token出现过的文档总数; - 在对应的文档中一个
token出现的总次数; token在文档的顺序;- 文档的长度;
- 所有文档的平均长度。。。
早期的全文检索
为整个文档集合建立一个很大的倒排索引并将其写入到磁盘。 一旦新的索引就绪,旧的就会被其替换,这样最近的变化便可以被检索到。
优点:
- 不需要锁;
- 被读入内核的文件系统缓存,留在那。大部分请求就会走内存;
- 单个的倒排索引允许数据被压缩,减少磁盘 I/O 和需要被缓存到内存的索引的使用量。
动态更新索引
要保留上面的不变性实现倒排索引的更新。
用更多的索引。
之前要反映最近的修改需要重写整个倒排索引,现通过增加新的补充索引来实现。
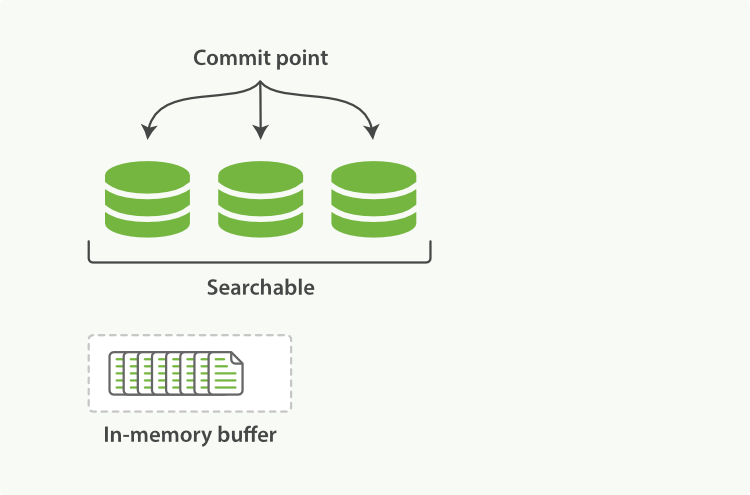
增加了提交点的概念。提交点是列出了所有已知段的文件。
有点类似于
Git的Commit。
- 新文档被收集到内存缓存;
- 不时地,缓存被提交:
- 新的段(追加的倒排索引)写入磁盘。
- 新的包含新段名字的提交点被写入磁盘。
- 磁盘
fsync,在文件缓存系统中的所有等待的写都刷新到磁盘保证物理写入。
- 新的段被开启,让它包含的文档可以被搜索;
- 内存缓存被清空,等待新的文档。
删除 & 更新
不能从段中移除,不能修改就的段。
每个提交点包含一个 .del 文件,文件中列出这些被删除文档的段信息。
当文档被删除时,只是在 .del 文件中被标记删除。扔可被查询匹配到,但最终结果被返回前从结果集移除。
轻量级实现新文档可搜索
每次索引一个文档去 fsync 代价很大。
ES - 文件缓存 - 磁盘。
文件在缓存后就可以被打开和读取了。
Lucene 允许新段被写入和打开—使其包含的文档在未进行一次完整提交时便对搜索可见。
使用 refresh 写入和打开一个新段的轻量的过程。默认每个分片每秒自动刷新一次。
POST /_refresh
POST /blogs/_refresh
PUT /my_logs
{
"settings": {
"refresh_interval": "30s"
}
}
持久化变更
在每秒刷新间隔中,若出现宕机,为了确保数据在失败中恢复。增加了 translog或事务日志。
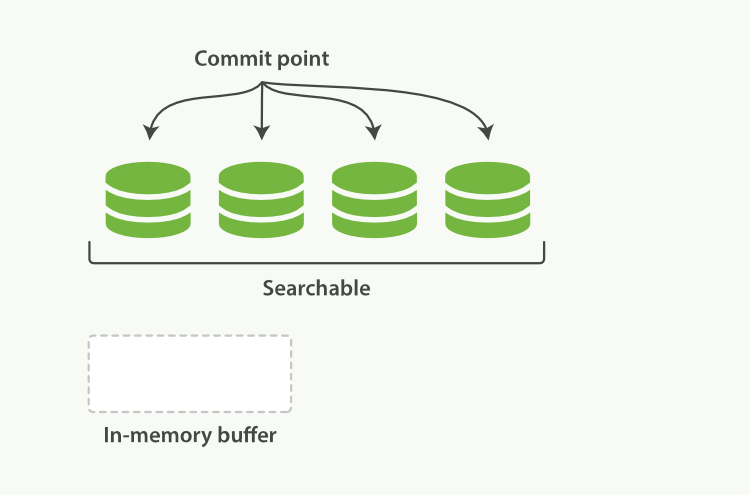
- 上述新文档被添加到
in-memory buffer并被加到了Translog(事务日志);
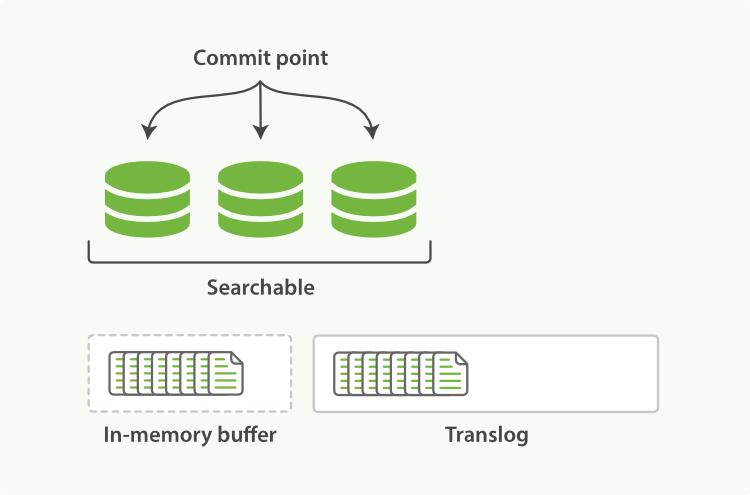
- 每秒刷新一次;
In-memory Buffer中的文档被写入一个新的段中,并不进行fsync;- 段打开,使其可搜索;
In-memory Buffer被清空。
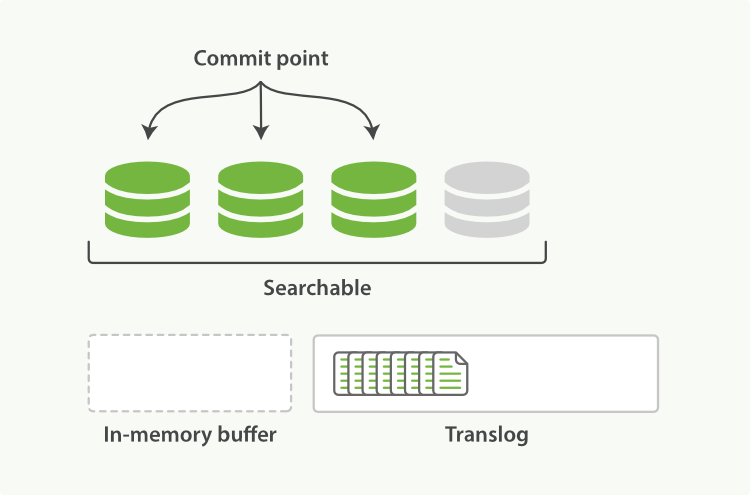
- 每隔一段时间:
translog变大,索引被刷新。一个新的translog被创建,一个全量提交被执行。- 所有在内存缓冲区的文档都被写入一个新的段。
- 缓冲区被清空。
- 一个提交点被写入硬盘。
- 文件系统缓存通过
fsync被刷新(flush)。 - 老的
translog被删除。
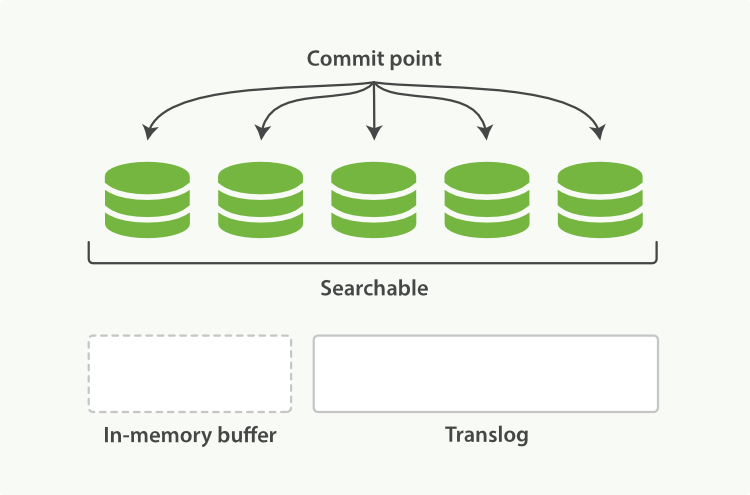
translog被用来提供实时CRUD。首先检查translog任何最近的变更。总能实时获取文档的最新版本。
执行一次提交并截断 translog 的行为称作一次 flush。
- 分片每
30s自动刷新; translog太大时刷新。
translog 文件被 fsync 到磁盘的频率:
- 每 5s;
- 每次写请求完成后执行。会带来一些性能损失,但是相对较小。
段合并
自动刷新每秒创建新段。
- 会消耗文件句柄、内存、CPU;
- 每个搜索请求比训轮流检查每个段。越多越慢。
在后台进行段合并解决。小 -> 大 -> 更大。
深入搜索
结构化搜索
探寻具有内在结构数据的过程。
- 简单的进行包括或者排除;
- 不关心评分。
curl -X GET "localhost:9200/my_store/products/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"price" : 20
}
}
}
}
}
'
在非评分查询时同时执行:
- 查找匹配文档;
- 创建
bitset,描述哪个文档包含这个term;roaring bitmap作为内部数据结构。
- 每个查询生成
bitset,迭代bitset找到满足的集合; - 缓存非评分查询而获取更快的访问,每个索引跟踪保留查询使用的历史状态。
- 如果最近的
256次查询备用到,候选缓存。只有超过10000的文档才汇缓存; - 缓存淘汰基于
LRU。
- 如果最近的
组合过滤器
{
"bool" : {
"must" : [],
"should" : [],
"must_not" : [],
}
}
curl -X GET "localhost:9200/my_store/products/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"productID" : "KDKE-B-9947-#kL5"}},
{ "bool" : {
"must" : [
{ "term" : {"productID" : "JODL-X-1937-#pV7"}},
{ "term" : {"price" : 30}}
]
}}
]
}
}
}
}
}
'
聚合
桶 & 指标
- 桶:满足特定条件的文档的集合;
- 指标:简单的数字预算。
聚合 = 桶 + 指标。
curl -X GET "localhost:9200/cars/transactions/_search?pretty" -H 'Content-Type: application/json' -d'
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"make": {
"terms": {
"field": "make"
}
}
}
}
}
}
'
对 color 进行聚合后对 make 进行聚合,指标为 平均 price。
按时间查询
curl --request GET \
--url http://192.168.110.173:9200/_search \
--header 'content-type: application/json' \
--data '
{
"size" : 0,
"aggs": {
"sales": {
"date_histogram": {
"field": "sold",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count" : 0,
"extended_bounds" : {
"min" : "2014-01-01",
"max" : "2014-12-31"
}
}
}
}
}
'
统计再聚合
curl -X GET "localhost:9200/cars-transaction/_search?pretty" -H 'Content-Type: application/json' -d'
{
"size" : 0,
"aggs": {
"sales": {
"date_histogram": {
"field": "sold",
"interval": "quarter",
"format": "yyyy-MM-dd",
"min_doc_count" : 0,
"extended_bounds" : {
"min" : "2014-01-01",
"max" : "2014-12-31"
}
},
"aggs": {
"per_make_sum": {
"terms": {
"field": "make"
},
"aggs": {
"sum_price": {
"sum": { "field": "price" }
}
}
},
"total_sum": {
"sum": { "field": "price" }
}
}
}
}
}
'
过滤 & 过滤桶 & 后过滤
数据建模
处理关联关系
应用层连接
多次分别查询数据,返回后合并。
非规范化数据
每个文档保持一定数量的冗余副本。
字段折叠
PUT /my_index/_mapping/blogpost
{
"properties": {
"user": {
"properties": {
"name": {
"type": "string",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}
}
}
嵌套对象
PUT /my_index
{
"mappings": {
"blogpost": {
"properties": {
"comments": {
"type": "nested",
"properties": {
"name": { "type": "string" },
"comment": { "type": "string" },
"age": { "type": "short" },
"stars": { "type": "short" },
"date": { "type": "date" }
}
}
}
}
}
}
指定类型为 nested。
查询:
GET /my_index/blogpost/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "eggs"
}
},
{
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "john"
}
},
{
"match": {
"comments.age": 28
}
}
]
}
}
}
}
]
}}}