Inside the machine
Inside the machine
1. Introduction
Calculator Model
instruction stream + data stream = output stream
File-Clerk Model
a reader, writer, modifier of numbers.
访问大量的序号为了 altering that store to 完成目标。
强调的时计算最终的产物,而不是计算本身。
计算机就是到处乱换数字,读,写,清除,重写不同地方的不同数字
- 一系列的输入 read
- 一系列的处理输入 modify
- the prior history of all the inputs that the computer has seen since it was last reset(write)
Stored-Program Computer
- Storage: 至少一个 number-holding 数据结构用于读写;
- ALU:在数字上操作的设备;
- BUS: ALU 通过
DATA BUS读写数据。- Code Stream 以一系列计算指令。
- 这些指令的操作数形成了 Data Stream,从存储区域通过 Data Bus 流入 ALU。
- 结果流通过
Data Bus流出到指定区域。
Code Stream
指令类型
- 算数指令
- 内存访问指令
DLW-1 内存指令格式: instruction source, destination
load #12, A
// 从 D 中读取数,再以这个数为内存地址访问其内容,将内容写入 A
// 这样做看起来累赘,可以用于 寄存器相对地址。
load #D, A
load #(D + 108), A
基地址 e.g.
OS 总是将程序数据段(Data Segment)的起始地址存入 D。
为了能够快速计算地址 基地址 + 偏移量,有一个 load-store unit 做非常快的整数加法。
有了上面的方式,程序员就可以不需知道数据的准确地址编写程序。
因为内存地址 和 整数值 都存在相同的寄存器。所以这些寄存器被称为通用寄存器。
2. 程序执行机制
指令映射到二进制字符串,这些计算机能懂的被称为 opcode。
计算指令的二进制格式
算数指令
0 123 45 67 89 101112131415
mode opcode source1 source2 destination 000000
mode: 0 - 指令是寄存器类型, 1 - 立即数类型
mode = 1 时
0 123 45 67 89101112131415
mode opcode source destination immediate value
add C, 8, A
内存访问指令
load 指令
load immediate
0 123 45 67 89101112131415
mode opcode 00 destination immediate value
load #12, A
load 指令类似
程序以有序的指令顺序存储在内存中,内存按线性地址排序。每一个指令都在自己的内存地址中。
获取指令
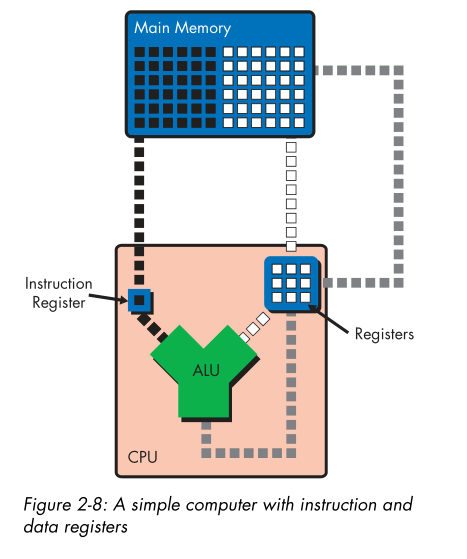
fetch 是特殊类型的 load,自动发生在每个指令上。将 program counter中当前内存 作为 source,instruction register 作为 destination。控制单元使用 fetch 将内存中的指令加载到寄存器中。指令接着被 decode 接着执行。
在 decode 的时候,通过增长 pc 中地址的值将下一条指令的地址放入 pc
- Fetch
- Decode
- Execute
分支指令
- 无条件分支
jump #target
- 条件分支
比如根据前条算数指令的值是 0 还是 > 0, < 0 决定是否跳转。而判断的结果存在 processor status word 中某个 bit 中。
通过检查 PSW 中某个 bit 来决定是否跳转。
sub A, B, C
jumpz #106
add A, B, C
如果 C == 0, 通过检查 psw 中某个 bit 满足则将 106 放到 pc 中。否则,照旧执行以一条指令。
分支指令作为 Load 的特殊类型指令
其实 #target 作为 source, pc 作为 destination。
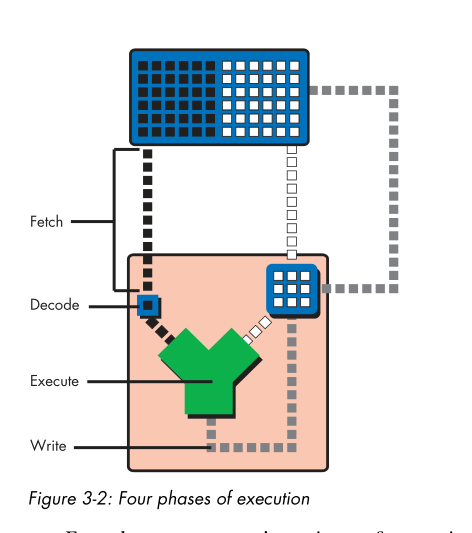
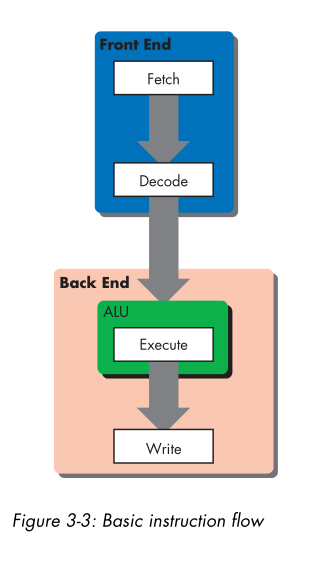
3. 流水线执行
- Fetch
- Decode
- Execute
- Write(“write-back”)

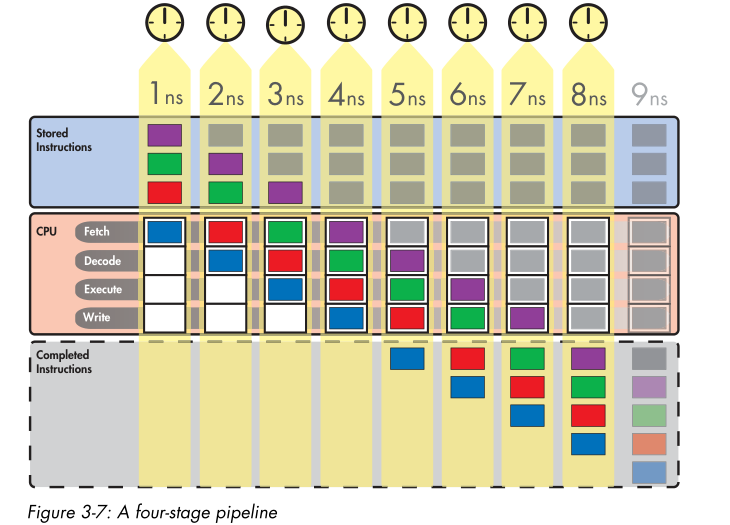
程序执行时间 = 程序指令条数 / 指令完成率
Instruction Throughput(Instruction per clock, IPC)
流水线失速
4. Superscalar(超标量)执行
指令级别并行。一个 clock cycle(时钟周期) 同时分派多个指令给不同的执行单元。
execution unit: 执行指定类别的指令。
处理器操作的数可以分为:整数和浮点数。这俩又可分为 scalar(一个数) 和 vector(多成分数)。
操作于数的操作又可分为:算数 和 逻辑。
ALU:算数和逻辑单元;IU(Integer Unit)SIU(Simple Integer Unit)CIU(Complex Integer Unit)
FPU(Floating-point Unit)
MAU:内存访问单元LSU(Load-Store Unit):执行 load store 指令,同时也负责address generationBEU(Branch Execution Unit):执行条件分支指令。有自己的address generation unit。
ISA:an abstract model of a machine for which a programmer writes programs.
microcode engine:a CPU within a CPU.
主要将特定的指令集翻译成一系列控制芯片内部的一些列命令。
ISA 代表理想模型,被底层硬件模仿。
hazards: 两个算数指令无法安全的并行分派模拟执行。
- Data:
add a b c; add c d d;假如pipeline或者superscalar不处理会有问题。forwarding:ALUoutput port 直接到 input port。减少了第一个指令write阶段。Register Renaming:实际上又很多general-purpose register,再程序员的角度看到的用到的名称。
- Structural:处理器没有足够的资源来同时执行。
- Control:Branch
- 失速:插入几个 bubbles
- 分支预测
Register File: CPU 的 registers 分组到特殊的单元 Register File。这个单元是一个内存数组,被一个特殊的接口访问允许 ALU 读写特殊的 register。
接口由一个数据总线(data bus) 和两个端口(read port & write port)组成。
从 register file 读取一个寄存器中的一个值: ALU 访问 register file 的 read port 并从一个位于数据总线上与 ALU 共享的特殊的寄存器获取。
一个 read port 允许 ALU 一次访问一个 register。所以 add 取 2 个数,需要两个 read port 和一个 write port。
5. 英特尔奔腾[Pro]
integer pipeline:
- Prefetch/Fetch
- 到缓冲(buffer),标注和分离每条指令的边界。
- Decode-1
- 解码到奔腾内部指令格式,告诉处理器执行单元如何操纵数据流;
- 包含了分支单元,检测当前被解码的指令是否是一个分支,分支预测也在这里发生。
- Decode-2
- 额外地址计算,因为 x86 支持更复杂地址模式;
- microcode ROM,解码长指令。
- Execute
- Write-back
分支单元和分支预测
- branch execution unit
- branch prediction unit
当解码器解码到一个分支指令,解码器将其发给 BU(分支单元)。BU 再将其发给其他执行单元评估指令的分支情况。如果分支成立,则将 target address 计算后告知前端并开始 fetch。
老的处理器就只能傻等。而现代处理器使用了 speculative execution(投机执行):进行有根据的猜测,在评估分支情况前执行新的分支。
投机执行的指令必须等评估完分支条件后才能写入 register file:如果 BPU 评估分支正确,投机执行的指令被标记为非投机并如同普通指令一样写回结果。
- 静态预测
- 假定向后分支将会发生,向前的分支不会发生。向后分支,是指跳转到的新地址比当前地址要低。这有助于配合经常出现的程序的循环控制结构。
- 如果程序充满循环则工作的不错。反之则不行。
- 动态预测
- 两个表记录已经执行分支的信息:
- branch history table: 记录最后几个时钟周期执分支的执行的可能性
- branch target buffer: 之前执行分支的
branch target
- 两个表记录已经执行分支的信息:
后端
Integer ALUs
非对称,有一个复杂、接活多。
Floating-Point ALU
前后端解耦
静态
指令 fetch、decode 然后使用硬件规则来决定指令是否能并行执行。control unit 将他们发给两个 ALU 在一个时钟周期同时执行。
缺陷:
- 动态的
ever-changing的代码流适应性差; - 超标量硬件没啥用。
动态
- issue 阶段
分派新解码的指令到一个位于前端和 ececution units 中间的缓冲中。当缓冲收集了少数等待执行的指令后。
在考虑处理器状态和执行现有的资源后在最适合的时间以及最优的顺序 issue 指令。
从缓冲中 issue 到 execution unit 的指令当执行完成后必须还原回程序顺序。这就需要第二个缓冲。
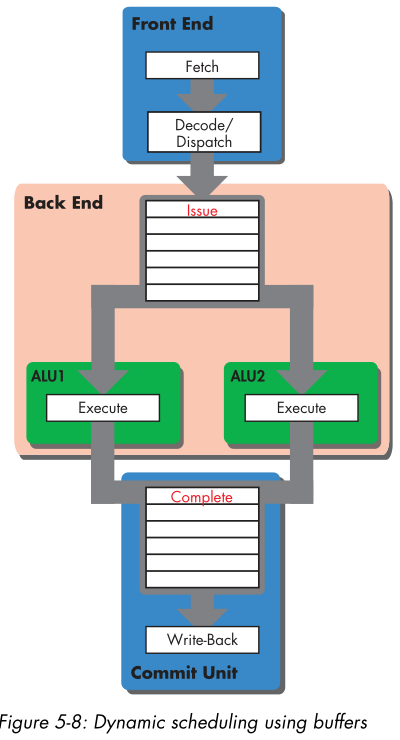
out-of-order execution,dynamic execution
- fetch
- decode/dispatch in order
- issue reorder
- execute out of order
- complete reorder
- write-back in order
So if an instruction is preceded by a pipeline bubble, when it enters the issue buffer, it will drop down into the empty space directly behind the instruction ahead of it, thereby eliminating the bubble.
- completion 阶段
当乱序执行之后,结果到一个专门用于这个指令的特殊的重命名的寄存器。这个寄存器对程序员不可见。
intel P6: ROB(reorder buffer) 记录了所有流入后端乱序指令的必要信息保证所有执完的指令还原回程序顺序。
- 指令窗口
ROB 记录原序的 40 条指令。
Reservation Station 重排序指令 20条指令。作为指令窗口在 ROB 中移动。