DDIA 笔记
DDIA 笔记
1. 可靠性,可扩展性,可维护性
可靠性
“即使出现问题,也能继续正确工作”
- 原因:故障(
fault)系统的一部分状态偏离其标准;、- 硬件故障(
hardware faults)随机的、相互独立的; - 软件错误(
systematic error) - 人为错误
- 硬件故障(
- 应对:容错(
fault-tolerant)或韧性(resilient)。
可扩展性
描述系统应对负载增长能力。
负载:用负载参数(load parameters)的数字来描述。
qps;- IO R/W rate;
- 活跃用户数量;
- 缓存命中率等。
当负载增加会发生什么:
- 增加负载参数并保持系统资源(CPU、内存、网络带宽等)不变时,系统性能将受到什么影响?
- 增加负载参数并希望保持性能不变时,需要增加多少系统资源?
上面问题需要性能数据:
- 吞吐量(
throughput);- 每秒可以处理的记录数量;
- 在特定规模数据集上运行作业的总时间。
- 响应时间(
response time)客户端发送请求到接收响应之间的时间。- vs. 延迟
- 延迟(
latency): 请求等待处理的持续时长,休眠状态,等待服务; - 响应时间 = 服务时间(
service time) + 网络延迟 + 排队延迟。
- 延迟(
- 可以测量的数值分布(
distribution)- 中位数, p50;
- p95
- p99
- p999
- 尾部延迟(tail latencies),非常重要。最有价值客户。
- vs. 延迟
应对负载增长:
- 纵向扩展(
scaling up) - 横向扩展(
scaling out)
可维护性
2. 数据模型与查询语言
层层叠加的数据模型构建多数应用。
每层数据模型的关键问题:如何用低一层数据来表示。
- App Dev: 观察世界次啊用对象或数据结构,一起相应 API 建模;
- 存储数据结构:用通用数据模型,
JSON或XML或ER中的表以及图模型; - DB Dev: 如何以内存、磁盘或网络上的字节来表示数据;
- 硬件工程师: 电流,光脉冲,磁场或者其他东西来表示字节。
每个层都通过提供一个明确的数据模型来隐藏更低层次中的复杂性。
关系型
数据被组织成关系(表),其中每个关系是元组(SQL中称作行)的无序集合。
用于:典型的事务处理和批处理。
阻抗不匹配(impedance mismatch)
大多数应用程序开发都使用面向对象的编程语言来开发,用来转化数据表示和关系数据库元组的代码很冗繁,执行时也有不少耗时。这种应用程序和数据库表示信息的模式之间的不匹配有时也被称为impedance mismatch。
ORM 能减轻所需的代码数量。
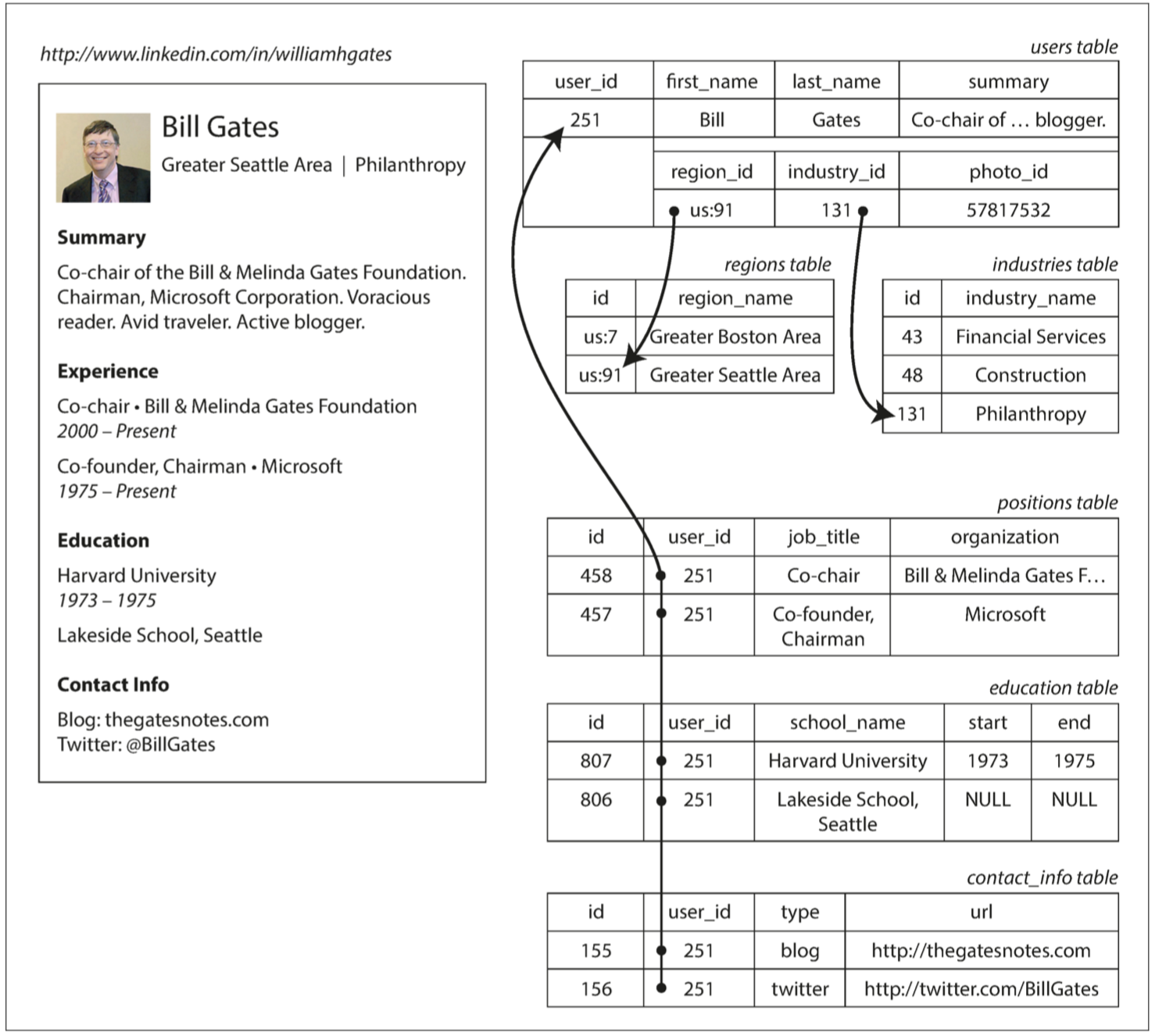
这里使用 user_id 作为标识。一对多的关系表示为:
- 单独的表中(
positions),对User表提供外键引用; - 结构化
JSON或XML存于列中; - 直接
JSON文档表示。- 更好的局部性,所有的相关信息再一个地方,一个查询足够;
- 一对多隐含了树状结构,
JSON使得这个结构明确。
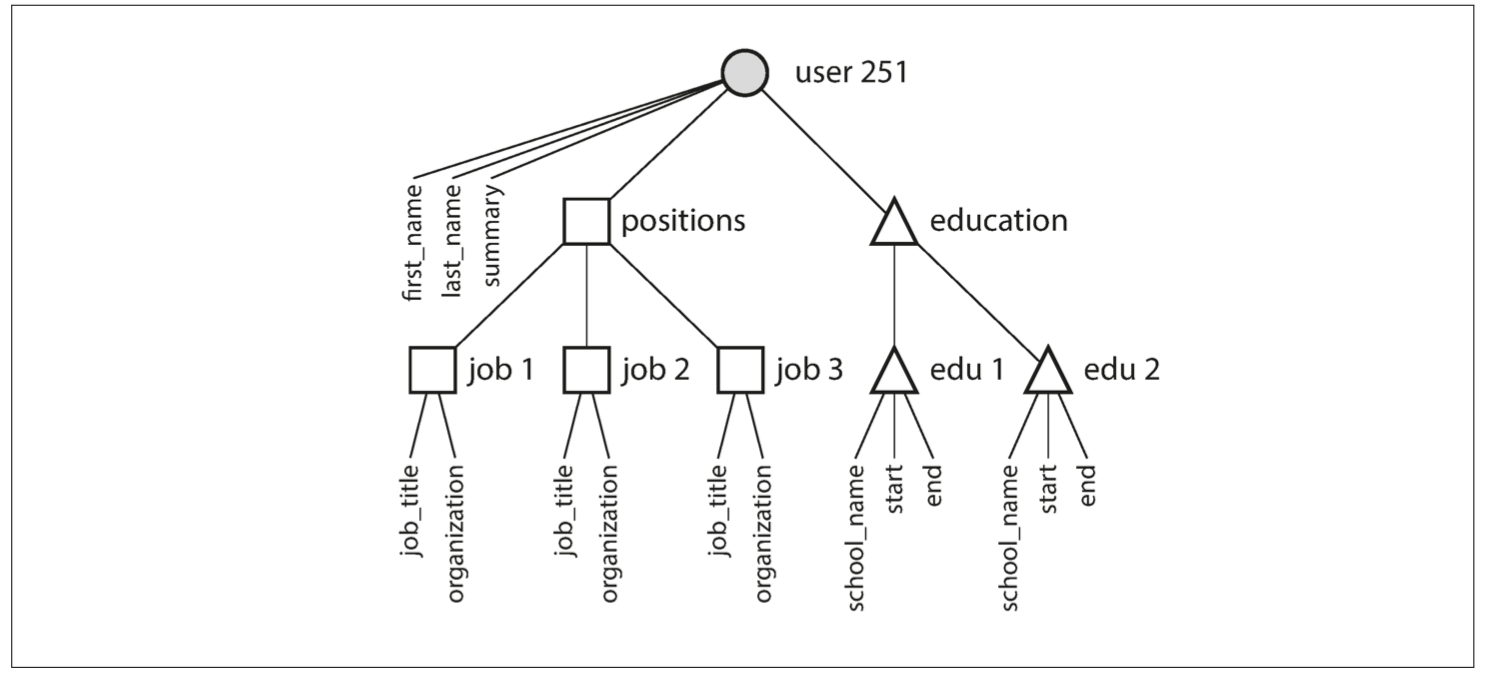
多对一和多对多
region_id 和 industry_id 是以 ID 而不是文本的形式。
这些可以通过标准列表选择或者文本框输入。选择的优势:
- 样式和拼写统一;
- 避免歧义;
- 易于更新——名称只存储在一个地方;
- 更好的搜索。
这其实是副本问题:
ID时对人类有意义的信息只存在一处,ID对人类没有任何意义,因而永远不需要改变;- 文本时则在用的每一处。
去除此类重复是数据库规范化(normalization) 的关键思想。
这种多对一的关系与文档模型不太吻合。
organization(用户工作的公司)和 school_name(他们学习的地方)只是字符串。或许应该是引用。
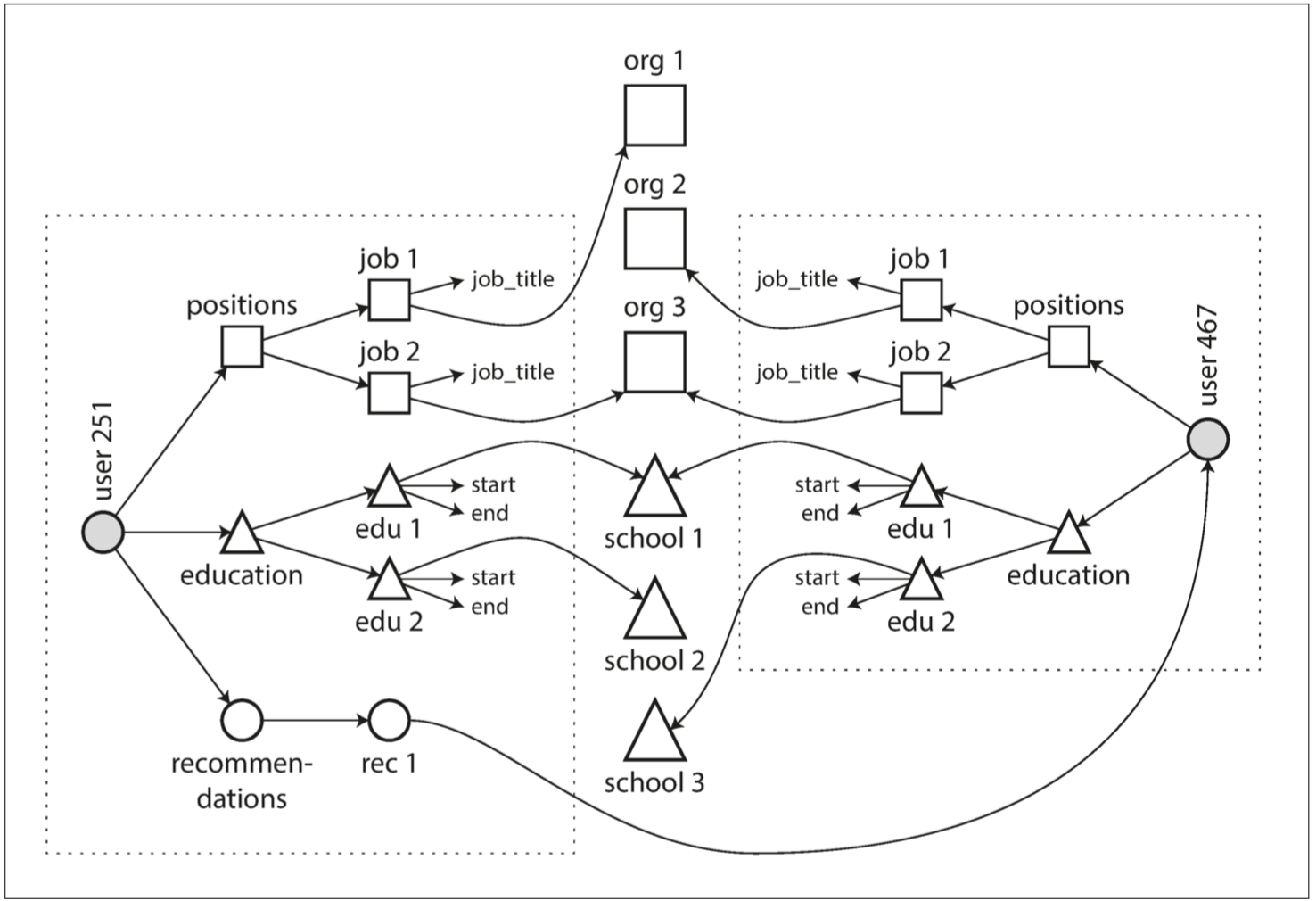
每个虚线矩形内的数据可以分组成一个文档,但是对单位,学校和其他用户的引用需要表示成引用,并且在查询时需要连接。
NoSQL
- 更好的可扩展性;
- 免费和开源;
- 关系模型不能很好地支持一些特殊的查询操作;
- 更具多动态性与表现力的数据模型。
3. 存储与检索
为什么要关心数据库内部存储与检索的机理?
你确实需要从许多可用的存储引擎中选择一个合适的。为了协调存储引擎以适配应用工作负载,你也需要大致了解存储引擎在底层究竟做什么。
存储引擎:
- 日志结构(log-structured)
- 面向页面(page-oriented)
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
#!eg
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}' $
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
日志(log),也就是一个 仅追加(append-only) 的数据文件。
而这查找是 O(n)。所以需要加 索引(index),是从主数据衍生的附加(additional)结构。
大致思想是,保存一些额外的元数据作为路标,帮助你找到想要的数据。
权衡。加快了查询速度,但是每个索引会减慢写入速度。
Hash
hash map
最简单的是保留内存中的 hash 映射。
追加一个文件,问题是如何避免耗尽磁盘空间。
简单的方案:分段、压缩。
- 日志分为特定大小的段;
- 当到指定大小时,关闭当前段,开新段;
- 压缩靠丢弃重复键,只保留每个键的最新值。