查漏补缺思维导图
查漏补缺
Java

JVM

MySQL



Redis

ES

分布式

Linux

网络

Spring

synchronized
原理
Synchronized 的语义底层是通过一个 monitor 的对象来完成,其实 wait/notify 等方法也依赖于 monitor 对象,这就是为什么只有在同步的块或者方法中才能调用 wait/notify 等方法,否则会抛出 java.lang.IllegalMonitorStateException 的异常的原因。
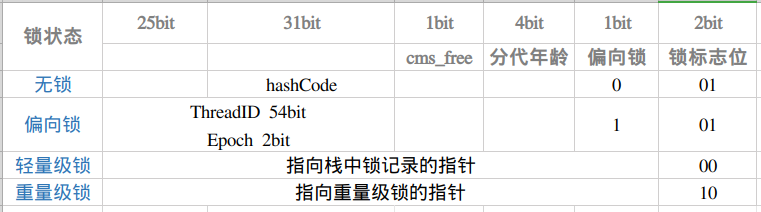
- monitorenter & monitorexit
- ACC_SYNCHRONIZED
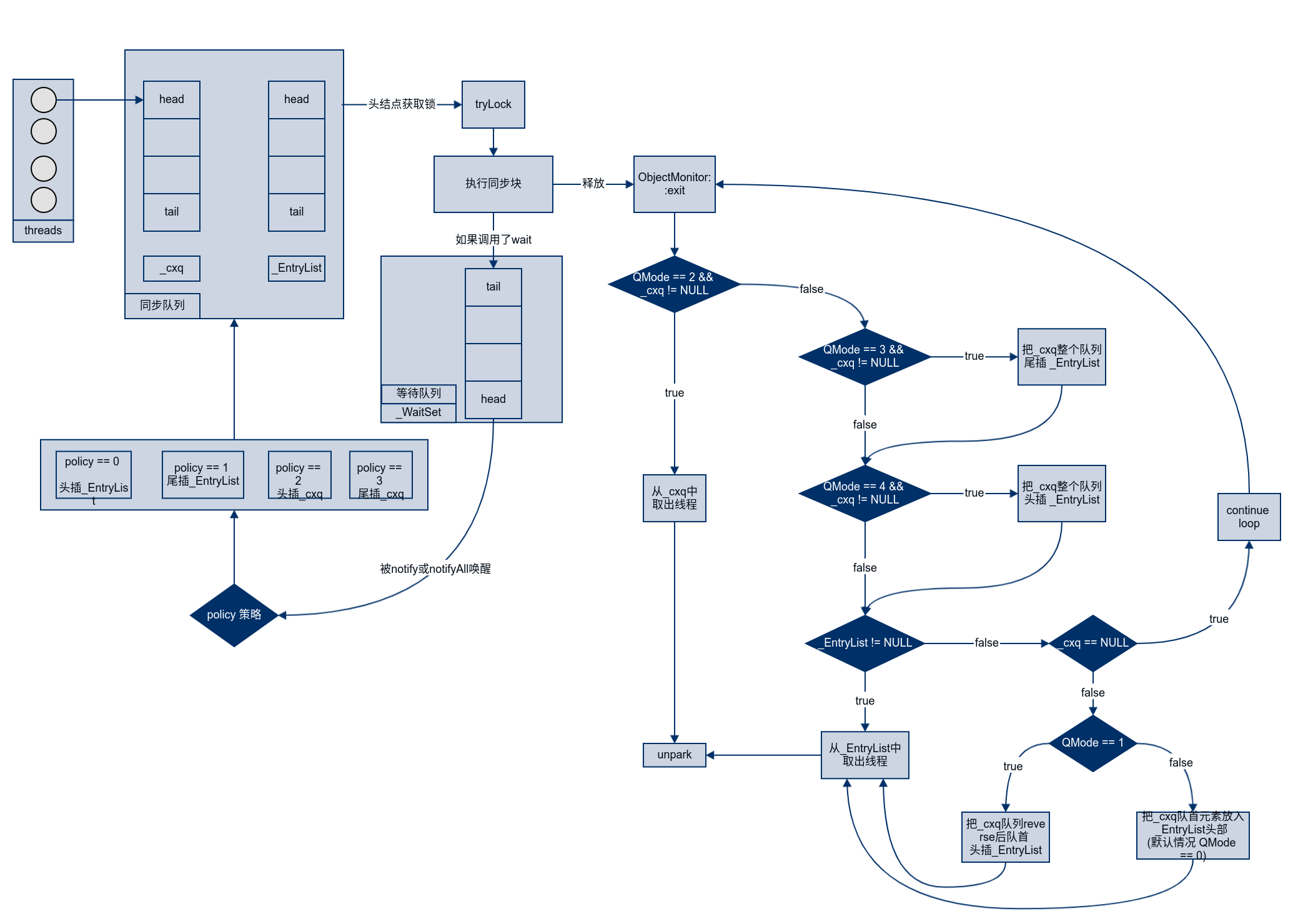
机制与 AQS 是很相似的,只不过 AQS 中是一个同步队列多个等待队列。
结构
ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0, // 等待中的线程数
_recursions = 0; // 线程重入次数
_object = NULL; // 存储该 monitor 的对象
_owner = NULL; // 指向拥有该 monitor 的线程
_WaitSet = NULL; // 等待线程 双向循环链表_WaitSet 指向第一个节点
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; // 多线程竞争锁时的单向链表
FreeNext = NULL ;
_EntryList = NULL ; // _owner 从该双向循环链表中唤醒线程,
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
_previous_owner_tid = 0; // 前一个拥有此监视器的线程 ID
}
_owner:初始时为NULL。当有线程占有该monitor时owner标记为该线程的ID。当线程释放monitor时owner恢复为NULL。owner是一个临界资源JVM是通过CAS操作来保证其线程安全的。_cxq:竞争队列所有请求锁的线程首先会被放在这个队列中(单向)。_cxq是一个临界资源JVM通过CAS原子指令来修改_cxq队列。- 每当有新来的节点入队,它的
next指针总是指向之前队列的头节点,而_cxq指针会指向该新入队的节点,所以是后来居上。
- 每当有新来的节点入队,它的
_EntryList:_cxq队列中有资格成为候选资源的线程会被移动到该队列中。_WaitSet: 等待队列因为调用wait方法而被阻塞的线程会被放在该队列中。
竞争
- 通过
CAS尝试把monitor的owner字段设置为当前线程。 - 如果设置之前的
owner指向当前线程,说明当前线程再次进入monitor,即重入锁执行recursions++, 记录重入的次数。(可重入性) - 如果当前线程是第一次进入该
monitor, 设置recursions为 1,_owner为当前线程,该线程成功获得锁并返回。 - 如果获取锁失败,则等待锁的释放。
等待
- 当前线程被封装成
ObjectWaiter对象node,状态设置成 `ObjectWaiter::TS_CXQ。 for循环通过CAS把node节点 push 到_cxq列表中,同一时刻可能有多个线程把自己的node节点 push 到_cxq列表中。node节点 push 到_cxq列表之后,通过自旋尝试获取锁,如果还是没有获取到锁则通过park将当前线程挂起等待被唤醒。- 当该线程被唤醒时会从挂起的点继续执行,通过
ObjectMonitor::TryLock尝试获取锁。
释放
当某个持有锁的线程执行完同步代码块时,会释放锁并 unpark 后续线程。
notify
notify 或者 notifyAll 方法可以唤醒同一个锁监视器下调用 wait 挂起的线程,将其放入 _EntryList。
线程池
线程获取任务
getTask()
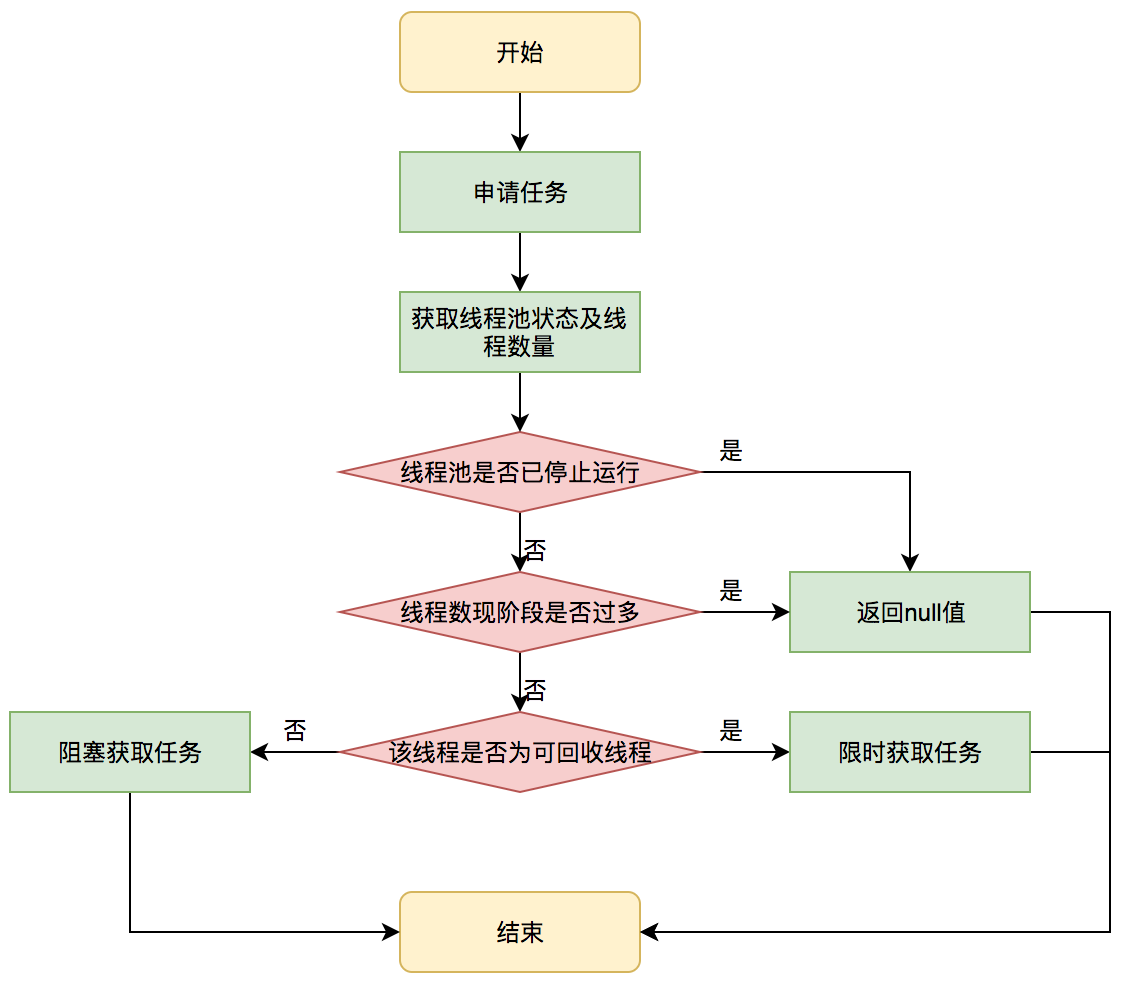
走👈🏻的是不可回收的核心线程,走👉🏻的是限 keepalive 时间,非核心线程 + 可回收的核心线程。
如果返回的是 null,则将 ctl cas(-1)。
调用 processWorkerExit 清理线程。
获取任务不为 null,会上自己的一把锁执行任务。
参数动态化
setCorePoolSize
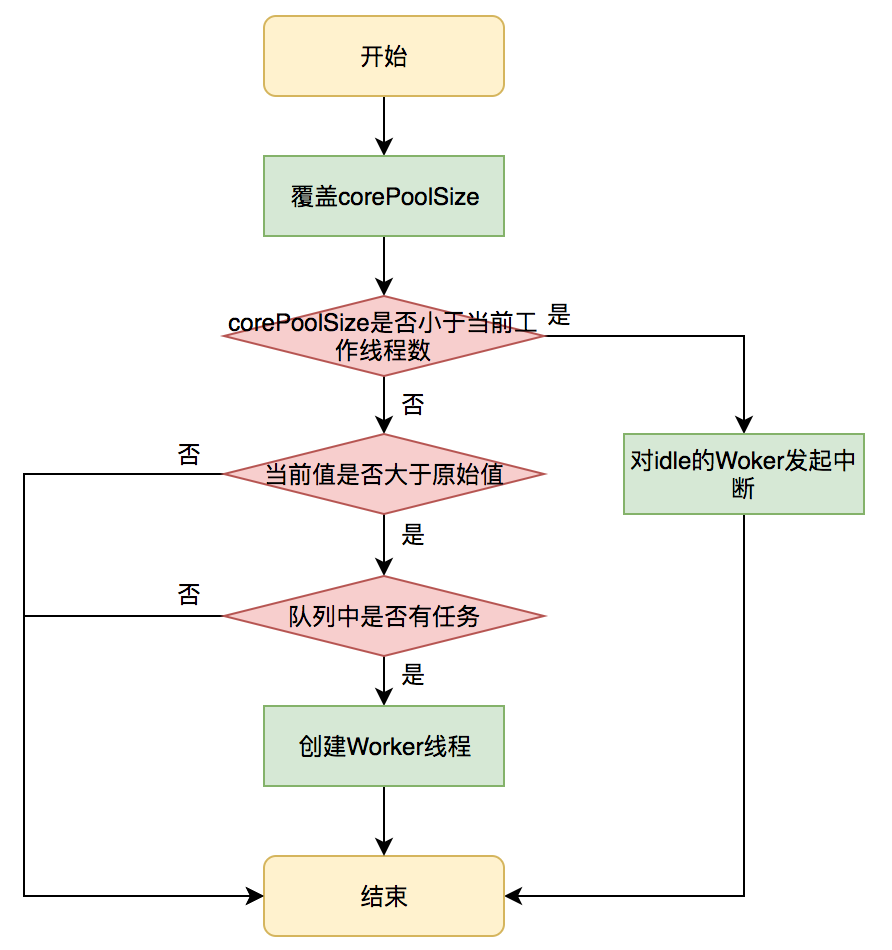
setKeepAliveTime
如果时间改小,则 interruptIdleWorkers。
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
Thread t = w.thread;
// 尝试获得锁成功,则表明其空闲
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
setMaximumPoolSize
interruptIdleWorkers。
异常处理
submit
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
// FutureTask::run
public void run() {
// ...
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
// 生吞了异常
setException(ex);
}
if (ran)
set(result);
}
} finally {
// ...
}
}
// FutureTask::setException
protected void setException(Throwable t) {
if (STATE.compareAndSet(this, NEW, COMPLETING)) {
// 将异常设置为结果
outcome = t;
STATE.setRelease(this, EXCEPTIONAL); // final state
finishCompletion();
}
}
private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V)x;
if (s >= CANCELLED)
throw new CancellationException();
// 抛出异常
throw new ExecutionException((Throwable)x);
}
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
// 获得结果
return report(s);
}
只有在 get() 时抛出异常。
execute
任务都是由 Worker 执行。
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
try {
task.run();
afterExecute(task, null);
} catch (Throwable ex) {
// 遇到异常,抛出异常
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
}
Redis Cluster
入门
6379服务客户端;16379cluster bus,节点间通信的二进制通道;- 故障检测
- 配置更新
- 故障转移授权
不使用一致性 hash,使用 hash slot。有 16384 slot,CRC16(key) mod 16384 来分配。e.g.
- Node A contains hash slots from 0 to 5500.
- Node B contains hash slots from 5501 to 11000.
- Node C contains hash slots from 11001 to 16383.
增删节点:
- 假如要 + D,就把 A,B,C 中的一些
hash slot - 假如要 - A,就把 A 中的
hash slot移动到B,C 中
hash tag
this{foo} 和 another{foo} 在一个 hash slot 中,可以在一条命令中执行多键操作。核心网络模型
master slave
A & B & C 每个增加一个 slave 节点。
B GG 后, B1 被选举新的 master。
一致性保证核心网络模型
特定情况下,可能回丢失系统向客户端确认的写入。
原因是使用异步复制:
- 客户端写入 master B;
- master B 回复 OK;
- master B 传播写到 B1, B2, B3。
丢失数据可能:
- 假如,master B 回复后, gg 了,还没来得及传播,B1 当选,就丢失了写数据。
如同其他数据库,每 s 同步到硬盘一样。可强制同步复制、写(WAIT),但是回降低性能。即使同步写也不能保证强一致性。
- 网络分区,B 和 客户端 Z1 与其他分区了。Z1 能写入 B。如果分区持续足够久时间让 B1 在分区的多数侧提升为 master,则 Z1 同时发送给 B 的写入将丢失。
node timeout: Z1 能够发送到 B 的写入量有一个 max window:如果分区的多数侧已经有足够的时间来选举一个 slave作为 master,那么少数侧的每个主节点都将停止接受写入
- 在经过
node timeout之后,一个master node被认为failing,可以被其复制节点取代; - 在节点超时过后,主节点无法感知大多数其他主节点,它会进入错误状态并停止接受写入。
规范
目标
- 1000 节点下高性能;
- 可接受的写安全,最大限度的保留客户端在大多数节点的写入;
- 可用性:能在大多数节点可访问的分区中存活下来。
实现的子集
- 所有的单 key 命令;
- 部分多 key 命令;
- hash tag
- 只有 db0,不能 select。
客户端和服务端扮演的角色
责任
- 存数据;核心网络模型
- 客户端持有
key->Node的映射能增加性能
- 客户端持有
- 自动发现其他节点;
- gossip 协议
- 发现不工作的节点;
- 发 ping 包
- 当 failer 发生时,提升 slave -> master
Redis Bus 为了达到上面目标,每个节点通过一个二进制的 TCP 协议连接来传递信息。
写安全
- 异步复制;
- 最后故障转移获胜。
相较于较少数的端,努力保留客户对于大多数端的节点的写入。
丢数据的情况:
- master 接收写,返回 OK,没有传播给 slave,unreachable 直到 slave 被推举。
- master 变分区,slave 被推举,master 回归,客户端未更新路由写入这个 master。
- 不太会发生,因为回归了,在一段时间内不会接收写入。
较少端的节点在 NODE_TIMEOUT 后拒绝写入。
可用性
replcas migration。
1-(1/(N*2-1)) 概率每个 master 有一个 slave。
性能
不是代理命令到正确的 node,redirect 客户端到正确的 node。
主要组件
key 分布模式
key 空间分割为 16384 个 slot。
CRC16 后 16bit 取 14 个,而 16384 = 2^14。
为什么选 14位?
node 属性
- 唯一的
name。160 bit随机字符串用hex表示; - ip & port
- flags
- pinged 最后时间
- 接收 pong 最后时间
- master 是谁
Nodes 握手
Redirection and resharding
MVOED
GET x
-MOVED 3999 127.0.0.1:6381
返回的是 hash slot 以及谁持有
ASK
容错性
心跳和 gossip 消息
heartbeat:
- ping
- pong
- 两个都包含重要的配置信息
- 每秒发 ping 给恒定数量的随机节点;
- 每个节点都确保 ping 未发送 ping 或接收到 pong 的时间超过 NODE_TIMEOUT 时间一半的所有其他节点。
假设 100 个节点, 60s 超时。每 30s 发 99 个 ping。总共 330 ping/s
心跳包内容
- Node ID;
- currentEpoch & configEpoch
- node flags,表明是 slave、master 和其他单字节的节点信息;
- 发送节点的 hash slot 的位图;如果是从节点,就主节点的位图;
- 发送者 BASE TCP 端口;
- 发送者视角的集群状态
- 如果是 slave,其 master
分布式锁
最简单
SETNX lock 1
- 程序处理业务逻辑异常,没及时释放锁
- 进程挂了,没机会释放锁
设置租期
SET lock 1 EX 10 NX
- 锁过期:客户端 1 操作共享资源耗时太久,导致锁被自动释放,之后被客户端 2 持有
可能评估操作共享资源的时间不准确导致的
- 释放别人的锁:客户端 1 操作共享资源完成后,却又释放了客户端 2 的锁
一个客户端释放了其它客户端持有的锁
解决锁被别人释放
// 加锁,使用 UUID
SET lock $uuid EX 20 NX
// 判断锁是自己的,才释放
if redis.call("GET",KEYS[1]) == ARGV[1]
then
return redis.call("DEL",KEYS[1])
else
return 0
end
解决锁过期时间不好评估
watchdog
仍存在的问题
主从集群 + 哨兵,主库宕机,从库自动提升为主库。主从切换时,这个分布式锁不安全。
总结
- 死锁:设置过期时间
- 过期时间评估不好,锁提前过期:守护线程,自动续期
- 锁被别人释放:锁写入唯一标识,释放锁先检查标识,再释放
RedLock
- 客户端先获取「当前时间戳T1」
- 客户端依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的
SET命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁 - 如果客户端从 >=3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果
T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败 - 加锁成功,去操作共享资源
- 加锁失败,向「全部节点」发起释放锁请求(前面讲到的 Lua 脚本释放锁)
Redis 线程模型
单线程事件循环
Redis 6.0- 核心网络模型是单 Reactor。
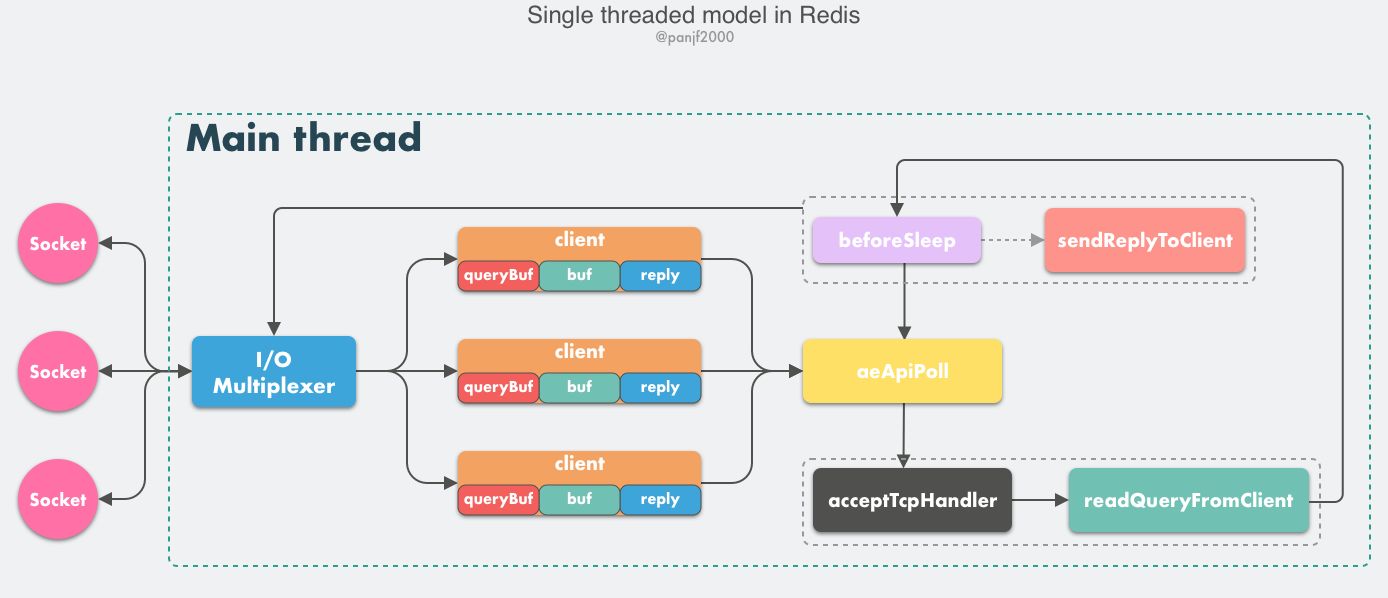
- client:
- *conn: socket 指针;
- *db: 选择的数据库;
- querybuf: 读入缓冲区;
- buf: 写出缓冲区;
- reply: 写出数据链表;
- aeApiPoll: Event Loop 的核心函数,监听等待读写数据触发
- acceptTcpHandler: 连接应答处理器。使用系统调用
accept接收来自客户端的新连接,为新连接注册绑定readQueryFromClient,以备后续客户端TCP连接; - readQueryFromClient: 命令读取处理器,解析并执行客户端的请求命令
- beforeSleep:
- sendReplyToClient: 命令回复处理器,当一次事件循环之后写出缓冲区中还有数据残留,则这个处理器会被注册绑定到相应的连接上,等连接触发写就绪事件时,它会将写出缓冲区剩余的数据回写到客户端。
工作原理:
- 启动,开启
Event Loop,注册acceptTcpHandler到端口对应的fd,等待新连接到来; - 客户端 & 服务端建立网络连接;
acceptTcpHandler被调用,主线程使用AE的API将readQueryFromClient绑定到新连接的fd,初始化一个client绑定这个客户端连接;- c -> r 发送请求命令,触发读就绪事件,主线程调用
readQueryFromClient读取客户端发送来的命令存入client->querybuf; - 调用
processInputBuffer,其中调用processInlineBuffer/processMultibulkBuffer解析命令,最后调用processCommand执行命令; - 根据请求命令的类型,分配相应的命令执行器执行,最后调用
addReply将响应写入client->buf(16KB) /client->reply(前面的不够,自动切换至此链表),最后把client添加到clients_pending_writeLIFO 队列; EventLoop主线程执行beforeSleep --> handleClientsWithPendingWrites遍历clients_pending_write调用writeToClient把缓冲数据写道客户端,如果还有数据,注册sendReplyToClient到写就绪事件,
多线程异步任务
Redis 4.0+
耗时的操作异步化,避免阻塞单线程的事件循环。
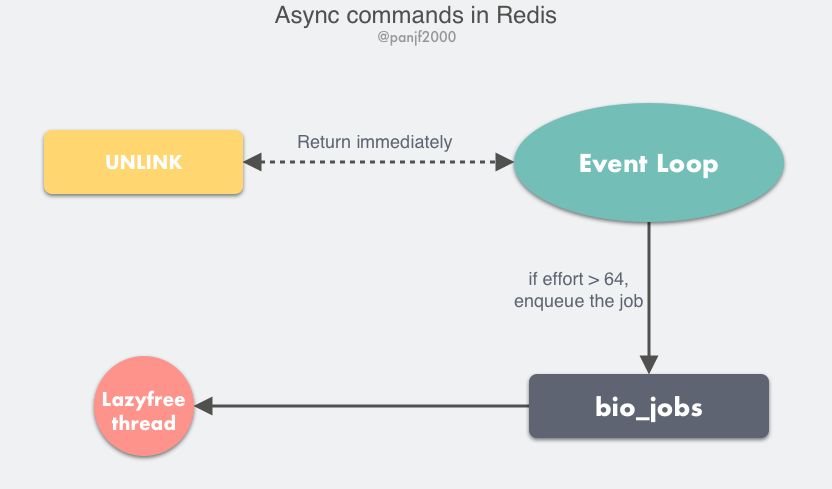
UNLINK:del异步版本,不会同步删除数据,只是key从keyspace中暂时移除,将任务添加到一个异步队列,最后由后台线程去删除。
多线程网络模型
I/O threading
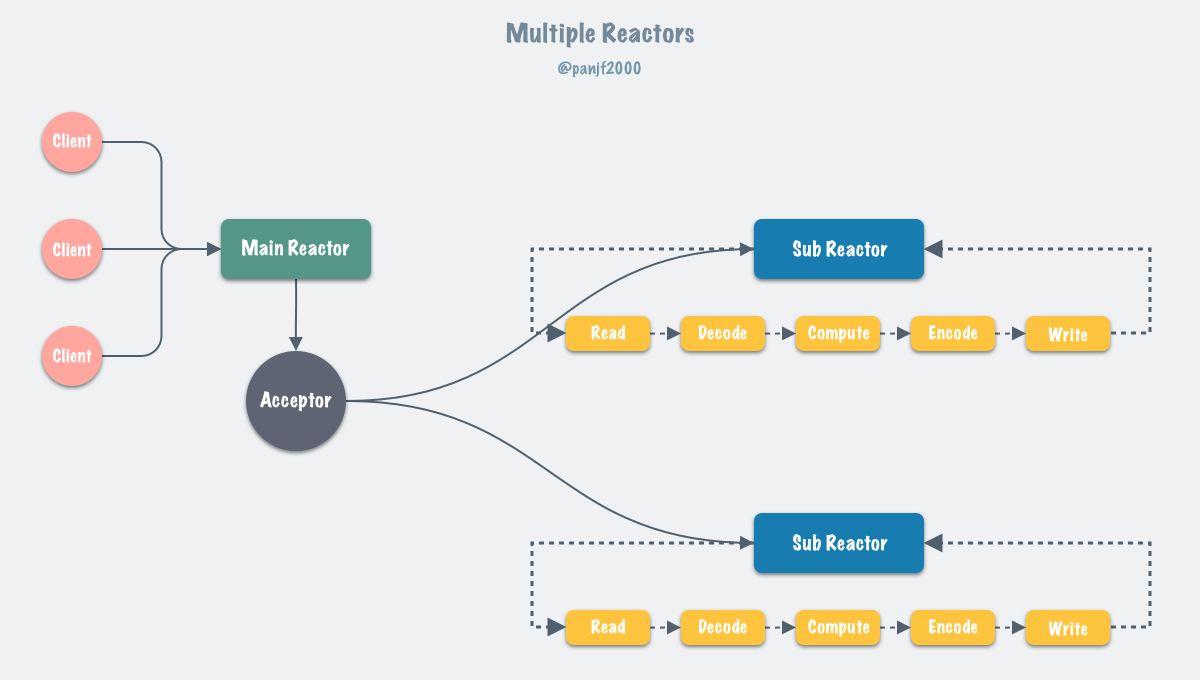
- 多个线程(Sub Reactors)各自维护一个独立的事件循环;
- 由 Main Reactor 负责接收新连接并分发给 Sub Reactors 去独立处理;
- 最后 Sub Reactors 回写响应给客户端。
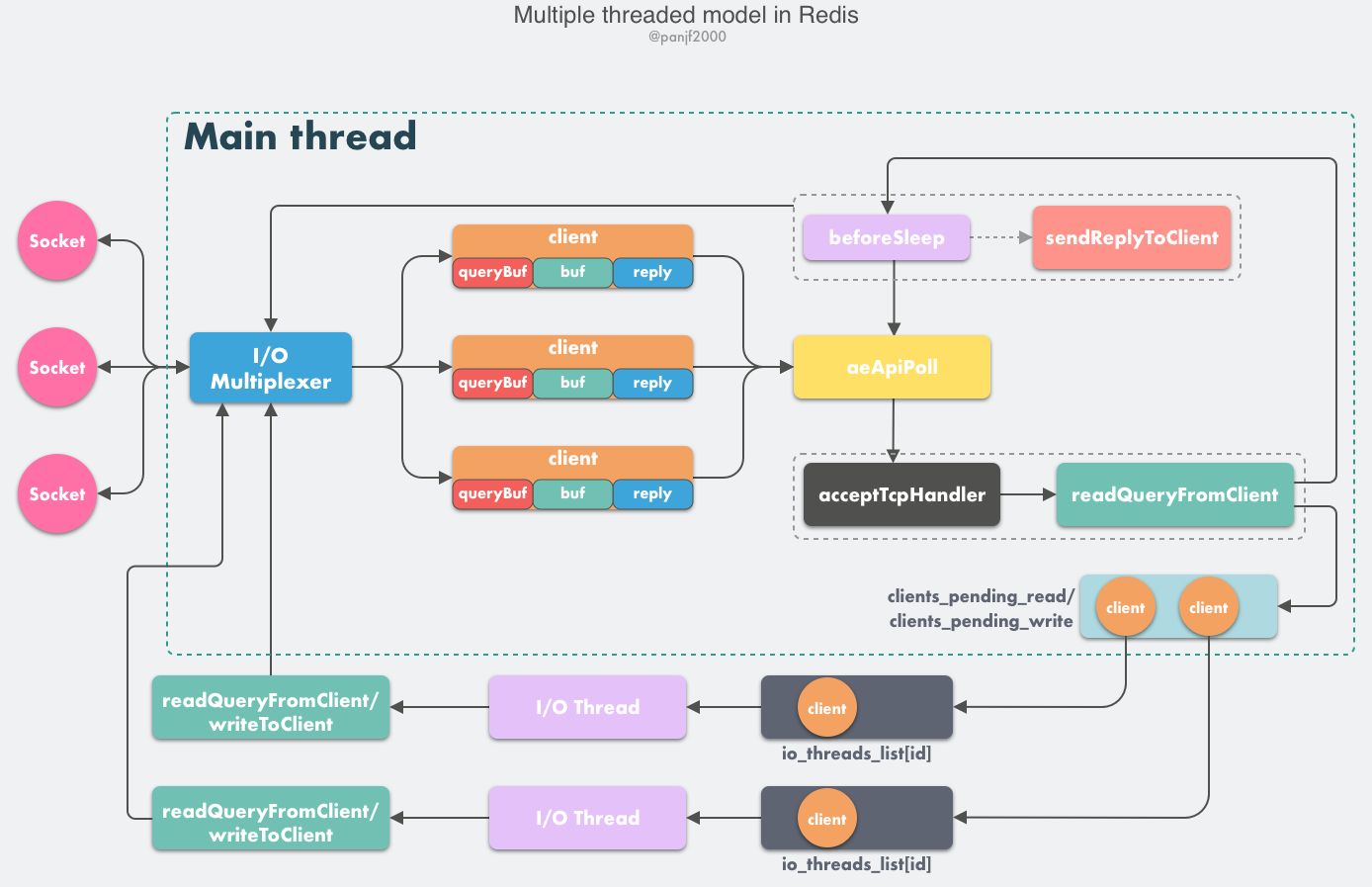
- client 发送请求,触发读就绪事件,主线程不会曲度 client 的命令,将
client放入 LIFO 队列clients_pending_read; - Event Loop 中,
beforeSleep -->handleClientsWithPendingReadsUsingThreads,利用 Round-Robin 轮询负载均衡策略,把clients_pending_read队列中的连接均匀地分配给 I/O 线程各自的本地 FIFO 任务队列io_threads_list[id]和主线程自己,I/O 线程通过 socket 读取客户端的请求命令,存入 client->querybuf 并解析第一个命令,但不执行命令,主线程忙轮询,等待所有 I/O 线程完成读取任务; - 主线程和所有 I/O 线程都完成了读取任务,主线程结束忙轮询,遍历
clients_pending_read队列,执行所有客户端连接的请求命令,先调用 processCommandAndResetClient 执行第一条已经解析好的命令,然后调用 processInputBuffer 解析并执行客户端连接的所有命令,…;
Redis Pipeline
RTT: c -> s & s -> c
客户端使用 pipeline,服务端被强迫使用内存 queue 响应。
最好批次设置合理的数字, 10K,读取响应,再发 10K。
- 只需要一次 RTT
- 极大提升了每秒能处理的操作的数量。 socket I/O 角度来看服务一条命令比较昂贵,调用
read()和write()系统调用, user -> kernel 切换。
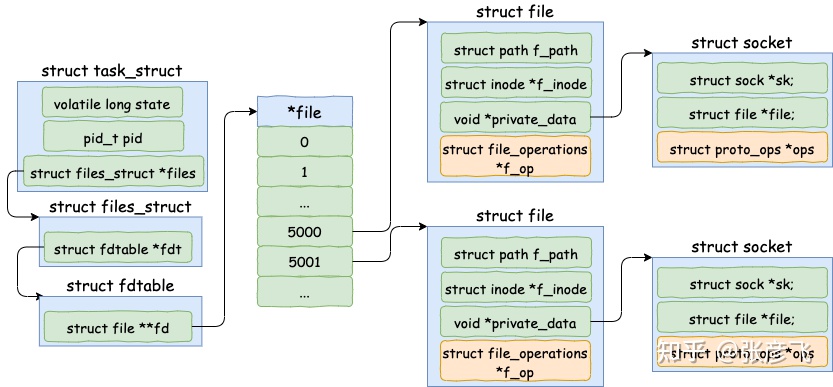
TCP 最多可建立多少个连接?
/proc/sys/fs/file-max: 当前系统可打开的最大数量
/proc/sys/fs/nr_open: 当前系统单个进程可打开的最大数量
nofile: 每个用户的进程可打开的最大数量
linux 下一切皆文件,包括 socket。所以每当进程打开一个 socket 时候,内核实际上都会创建包括 file 在内的几个内核对象。该进程如果打开了两个 socket,那么它的内核对象结构如下图。
TCP 三次连接
TCP 连接需要双方达成的共识:
- Socket
- 互联网地址标志符和端口
- 序列号
- 追踪通信发起方发送的数据包序号
- 接收方可以通过序列号向发送方确认某个数据包的成功接收
- 窗口大小
- 流控制
为什么需要三次握手?
- 阻止重复历史连接的初始化
- 对通信双方的初始序列号进行初始化
- 可能的问题:多次发送,数据被路由丢失,到达接收方无法按照发送顺序
-
- 接收方可通过序号去重
-
- 发送方对未 ACK 的重新发
-
- 接收方可按照序号排序
- 2 ? > 3 ?
- 2 次不够
-
3 浪费
缓存一致性
Cache Aside
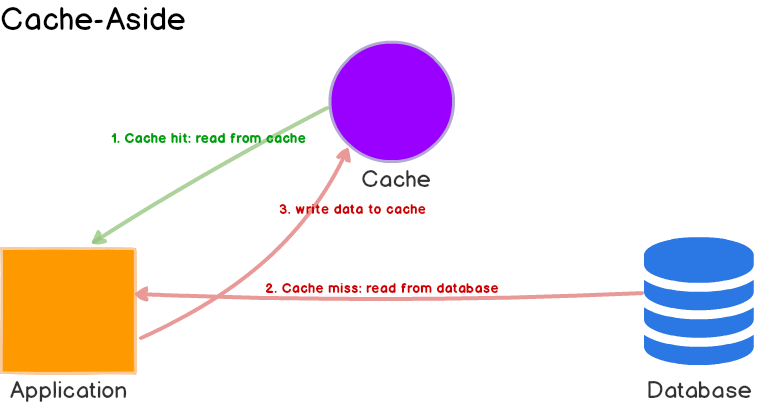
通用,多读的最适合。
优势:
- 缓存 down, 仍然可用;
- 缓存种的数据模型可与数据库种的不一样。
劣势:
- 写策略是直接写入数据,会造成不一致。
解决:
- 弱一致性:使用
TTL直到时间过去才能一致。 - 必须保证数据新鲜:invalidate 缓存条目或
Read Through
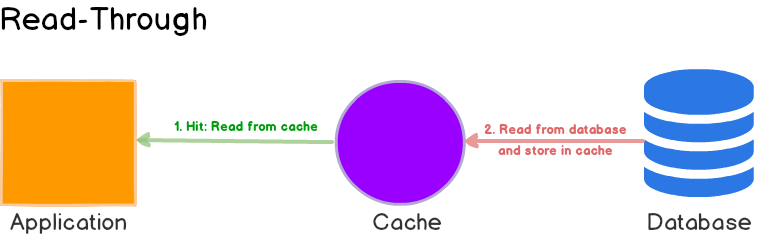
与 cache aside 的不同:
| Cache Aside | Read Through |
|---|---|
| 应用获取数据装配缓存 | 库或者独立缓存提供者 |
| 数据结构可以不一致 | 数据结构一致 |
优势:
- 适用于相同的数据被请求多次;
劣势:
- 可能造成缓存不一致,通过写入策略解决;
- 第一次请求,总是导致
cache miss导致过量的缓存加载。可以通过预热加载。
Write Through

先写缓存,再写数据库。
与 read through 配合。
Write Back
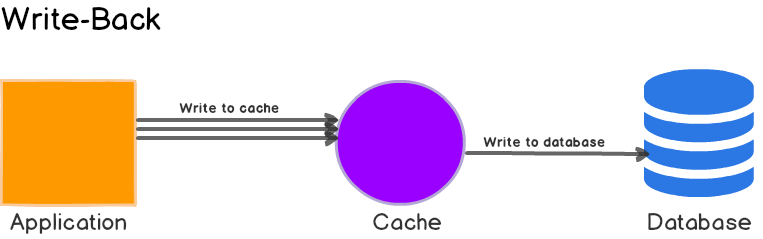
适用于重写。
与 read through 结合。