查漏补缺
查漏补缺
Java
@startmindmap
* Java
** 并发 & 同步
*** [[https://tech.meituan.com/2018/11/15/java-lock.html 锁事-美团]] synchronized
****_ [[https://xiaomi-info.github.io/2020/03/24/synchronized/ 原理-小米]],可重入性,可见性
****_ 锁升级
*** volatile
****_ 64 位写入的原子性,按照 slot 写入。64 位要写两次
****_ 可见性
****_ 内存屏障
****_ 内存屏障,保证指令不重排
*** 锁
**** 锁升级
***** 偏向锁
******_ 一直被一个线程所访问
******_ 在 **Mark Word** 里存储锁偏向的线程 **ID**
******_:
**撤销**:
只有遇到其他线程尝试竞争偏向锁时,
持有偏向锁的线程才会释放锁,
**不会主动释**放偏向锁。
**等待全局安全点**,暂停拥有偏向锁的线程,
判断锁对象是否处于被锁定状态。
恢复无锁(标志位为 01)或轻量级锁(标志位为 00)的状态
;
***** 轻量级锁
******_ 线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。
******_:
无锁状态:
在**当前线程的栈帧**中建立一个名为**锁记录**(Lock Record)的空间,
用于存储锁对象目前的 **Mark Word** 的拷贝,
然后拷贝对象头中的 **Mark Word** 复制到锁记录中。
CAS 操作尝试将对象的 **Mark Word** **更新**为指向 **Lock Record** 的指针,
并将 **Lock Record** 里的 **owner** 指针指向对象的 **Mark Word**。
更新**成功**: 线程就拥有了该对象的锁,锁标志位设置为“00”。
更新**失败**: 对象的 Mark Word 是否**指向当前线程的栈帧**?
只有当前一个等待线程,自旋;
自旋超过次数,或来第三个,膨胀。
;
*****_ 重量级锁:管程
****_:
**乐观**: 只是在更新数据的时候去判断之前有没有别的线程更新了这个数据,
没有被更新,当前线程将自己修改的数据成功写入。
已经被其他线程更新,则根据不同的实现方式执行不同的操作(报错或重试)
;
****_:
**悲观**: 使用数据的时候一定有别的线程来修改数据,
在获取数据的时候会先加锁,
确保数据不会被别的线程修改。
;
**** CAS
*****_ 乐观锁中的重试
*****_ **ABA问题**: AtomicStampedReference
*****_ **只能保证一个共享变量的原子操作**: AtomicReference
*****_ **循环时间长开销大**: 只能保证一个共享变量的原子操作
**** 死锁
***** 产生条件
******_ **互斥条件**:一个资源每次只能被一个进程使用。
******_ **占有且等待**:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
******_ **不可强行占有**: 进程已获得的资源,在末使用完之前,不能强行剥夺。
******_ **循环等待条件**: 若干进程之间形成一种头尾相接的循环等待资源关系。
***** 排查
******_ jstat $PID
******_ jcmd $PID Thread.print
******_:
ThreadMXBean bean = ManagementFactory.getThreadMXBean()
long[] threadIds = bean.findDeadlockedThreads()
;
**** reentrantlock
*****_ 实现原理,加锁和释放锁的一个过程
*****_ aqs
*****_ 公平和非公平
*****_ 可重入
*****_ 可中断
*** 并发工具类
**** concurrenthashmap
***** 怎么保证线程安全的
****** HashMap 为什么不安全
*******_ **多线程的put**可能导致**元素的丢失**
*******_ put和get**并发**时,可能导致**get为null**
****** synchronized + CAS
*******_ 读安全:使用 **volatile** 保证当 Node 中的值**变化时对于其他线程可见**
*******_ 写安全:使用 **table 数组的头结点**作为 synchronized 的**锁**来保证**写操作的安全**
*******_ 写安全:当头结点为 null 时,使用 **CAS** 操作来**保证数据能正确的写入**
*******_ 扩容安全:Synchronized 头节点,标记 moved,再插入的自旋等待
***** 为什么用 synchronized
******_ 头结点如果使用 ReentrantLock,需继承 AQS,增加内存
******_ 降低了锁粒度
******_ JVM 会优化 synchronized
*****_ 分段锁有什么问题
***** hash算法 (h ^ (h >>> 16)) & HASH_BITS
******_ 高位参与
******_ HASH_BITS 0x7fffffff,变正数
**** threadlocal
***** 什么场景下使用的
******_ MDC
******_ traceid
*****_ 原理: 每个线程有一个自己的ThreadLocalMap<ThreadLocal, V>
*****_:
hash冲突怎么办: 开放地址法,
不为 null,且已经过期,则启动探测试清理
;
*****_:
内存泄漏:key 是 WeakReference,不存在强引用时,自动回收
value 是强引用: Thread -> ThreadLocalMap -> Entry -> value
只有 Thread 被回收,value 才被回收。
;
*****_ 解决方法:用完后 remove
**** 线程池
*****_ 扩容实现
*****_ 线程回收: getTask() 返回 null,线程池只是维持引用,防止 JVM 回收
***** 核心参数
******_ corePoolSize
******_ maximumPoolSize
******_ keepAliveTime
******_ TimeUnit
******_ workQueue: BlockingQueue
******_ threadFactory
****** RejectedExecutionHandler:关闭了或者加不了线程处理了调用
*******_ AbortPolicy: 抛 RejectedExecutionException
*******_ CallerRunsPolicy
*******_ DiscardOldestPolicy:最早的出队,执行这个
*******_ DiscardPolicy:啥也不做
*****_ 线程数设置: IO密集型和CPU密集型
*****_ 参数动态调整后变化过程 *
*****_ 线程抛异常怎么办 *
** 线程
*** waiting vs. block
****_:
wait 要等待其他线程 notify
block 必须抢到执行机会
;
****_:
wait 可以被 inerrupted
block 不能被
;
*** 线程状态
****_ NEW
****_ RUNNABLE
**** BLOCKED
*****_ 等待 montor lock 进入同步区
*****_ Object.wait() 后阻塞重新进入同步区
**** WAITING
*****_ 无限 Object.wait()
*****_ 无限 Thread.join()
*****_ LockSupport.park
**** TIMED_WAITING
*****_ Thread.sleep
*****_ 有限 Object.wait()
*****_ 有限 Thread.join()
*****_ LockSupport.parkNanos
*****_ LockSupport.parkUntil
****_ TERMINATED
***_ interrupt()
** 集合
*** hashmap
****_ 原理, put & get
****_ 8转红黑树?
****_ 什么时候扩容? 0.75?
****_ 扩容步骤,为什么分高低位
** 代理
*** spring aop
**** 理解
*****_:
以不同于 OOP 的方式思考程序结构,模块化的关键是 Aspect
Aspect 能够实现跨越多种类型和对象的关注点(例如事务管理)的模块化。
;
*****_:
解决什么问题:
1. 提供声明式企业服务(事务);
2. 让用户实现自定义 Aspect,以 AOP 补充他们对 OOP 的使用。
;
*****_:
实现原理: 默认(实现了接口)动态代理,
配置了 Aspect,创建 Bean 时创建代理对象。
;
*** JDK 动态代理 & cglib
**** JDK 动态代理
*****_ InvocationHandler & Proxy.newProxyInstance
*****_ 优点:原生,生成代理类速度快
*****_ 缺点:必须实现接口,反射回调速度慢
**** CGLIB
*****_:
ASM字节码生成框架,直接对需要代理的类的字节码进行操作,
生成这个类的一个子类,并重写了类的所有可以重写的方法
;
***** 优点
******_ 不需要接口
******_ 原来类的子类可以对所有方法代理
******_ 效率高,和编写的普通类没啥区别
***** 缺点
******_ 需要继承,final 类 gg
******_ 重写方法,final 或 private 方法 gg
******_ 操作字节码,代理类生成较慢
** 反射
***_ [[https://www.cnblogs.com/chanshuyi/p/head_first_of_reflection.html 反射-陈树义]]原理
** NIO
*** 组件
****_ Channel
****_ Buffer
****_ Selector
***_ 实现原理
***_ 优缺点
***_ netty的设计模型,架构,使用场景
*** epoll
****_ LT(水平触发):读缓冲区不空,一直触发读事件;写缓冲区不满,一直触发写事件
****_ ET(边缘触发):读:空 -> 非空 只一次;写:满 -> 不满 只一次
** 引用类型
***_ **强引用**: 强引用
***_ **软引用**:SoftReference 修饰,在内存要溢出的时候被回收
***_ **弱引用**:WeakReference,发生 GC,就会被回收
***_ **虚引用**:PhantomReference,熄火时接到通知
@endmindmap
JVM
@startmindmap
* JVM
** 参数
*** 空间
****_ **Xms**: 堆初始大小
****_ **Xmx**: 堆最大大小
****_ **Xmn**: 堆年轻代大小
****_ **XX:SurviorRatio**: Eden / S0 = Eden / S1 = 8(Default)
****_ **XX:NewRatio**: 老年代 / 新生代 = 2(Default)
****_ **Xss**: 线程栈大小
*** GC 日志
****_ **XX:+PrintGCDetails**(9+,**Xlog:gc***)
****_ **XX:+PrintGCDateStamps** **XX:+PrintGCTimeStamps**(9+,**Xlog:gc*::time**)
****_ **Xloggc:/path/gc.log**(9+,**Xlog:gc:/path/gc.log**)
** 类加载器
*** 分类
****_ **Bootstrap**: <JAVA_HOME>/lib
****_ **Extension**: <JAVA_HOME>/lib/ext
****_ **Application**: getSystemClassLoader() + 用户路径
****_ 自定义加载器
*** 双亲委派
**** 机制
**** 三次破坏
*****_ **findClass()** 重写
*****_ **setContextClassLoader**: **JNDI** & **JDBC**,核心包 Bootstrap,实现位于用户定义。
*****_ OSGI
*****_ Java 9 Module
*** 类加载过程
**** 详细过程
*****_ 加载: 字节流加载到 JVM,生成类对象
***** 链接
******_ 验证: 文件格式、元数据、字节码、符号引用,
******_ 准备: 类静态变量分配内存并设置类变量初始值。
******_ 解析: 符号引用 -> 直接引用
*****_ 初始化: 执行 <clinit>()
****_ [[https://www.zhihu.com/question/30300585/answer/51335493 符号引用---R 大]]符号引用: 带有 类型(Ta)/ 结构的**字符串**
****_ 直接引用: 通过方法名找到对应的**方法指针**或者**虚函数表下标**
****_ 初始化过程
** GC
*** CMS
*** G1
*** gc roots: 一组必须活跃的**引用**
****_ **所有线程活跃栈帧**指向堆里的对象的引用
****_ **VM 的一些静态数据**结构里指向GC堆里的对象的引用
****_ 所有当前**被加载的Java类**
****_ Java类的引用类型**静态变量**
****_ Java类的**运行时常量池**里的**引用类型常量**(String或Class类型)
*** [[https://www.zhihu.com/question/41922036/answer/93079526 HotSpot GC---R 大]] 种类
**** Partial GC
***** Young GC
******_ 只 young
******_ **eden** 区分配满的时候**触发**
*****_ Old GC: 只 old,only __CMS__
*****_ Mixed GC: young + 部分 old,__G1__
**** Full GC
*****_ 收集整个堆,包括 young gen、old gen、perm gen
***** 触发
******_ 准备触发 young,之前统计的平均晋升大小 > 剩余 old
******_ perm gen 分配空间不够
******_ system.gc()
*** 什么对象进入老年代
****_ 大对象直接进
****_ 长期存活对象进入 + 动态年龄判断
****_ 空间分配担保,Survior 无法容纳的对象
***_ eden和survivor比例可以调整么,参数是什么,调整后会有什么问题
** OOM
***_ 排查
***_ 产生原因
** 内存区域
*** 内存结构
****_ 程序计数器
**** 虚拟机栈
***** 局部变量表
******_ 一组变量值存储空间
******_ 存放**方法参数**和方法内定义的**局部变量**
******_ 变量槽(Variable Slot)为最小单位
*****_ 操作数栈
***** 动态连接
******_ 包含一个指向**运行时常量池**中**该栈所属方法**的**符号引用**
******_ 运行时将**符号引用转换成直接引用**
*****_ 方法返回地址
******_ 正常返回出口
******_ 异常返回出口
****_ 堆
****_ 方法区
*** 操作数栈
****_ 操作数栈过程
****_ 方法返回地址什么时候回收
****_ 程序计数器什么时候为空
*** 对象一定分配在堆上么
****_ TLAB
****_ 标量替换
*** 对象内存布局
**** 对象头
*****_ 对象自身运行时的数据
*****_ 类型指针
*****_ [数组长度]
****_ 实例数据
****_ 对齐填充
** 前端编译与优化
***_ JIT
***_ 逃逸分析
@endmindmap
MySQL
@startmindmap MySQL 脑图
* MySQL
** Log [[https://zhuanlan.zhihu.com/p/58011817 MySQL日志分类及简介]]
***_ 错误日志
***_ 查询日志
***_ 慢查询日志 *
*** 事务日志
****_ 重做日志 (redo log)
****_ 回滚日志 (undo log)
***_ 二进制日志
***_ 中继日志
** InnoDB
***:
结构
[[https://zhuanlan.zhihu.com/p/235458760 深入剖析InnoDB]]
[[https://draveness.me/mysql-innodb/ 『浅入浅出』InnoDB]]
;
**** 内存中
***** 缓冲池(Buffer Pool)
******_ 缓存访问的索引和表数据
******_ 常用数据内存访问
******_ 80%+ 内存占用
******_ 划分为包含多行的链表连接的页,LRU 淘汰
***** 写缓冲区(Change Buffer)
******_ 内存:占用 buffer pool 的内存;硬盘渣弄 system tablespace
******_ 缓存不在 buffer pool 中的**二级索引**的修改
******_ 当其他读将页加载到 buffer pool 中合并,减少随机 IO
******_ 当系统空闲或者 slow shutdown 周期性将更新的索引写盘
***** 日志缓冲区(log Buffer)
******_ 持有写入硬盘的 log 文件的数据
******_ 周期性刷盘
******_ 更大可以使运行大事务不需要在提交事务前写入 redo log 数据到硬盘
*****_ 自适应 Hash 索引
**** 硬盘中
***** Double Write Buffer
******_ 事物原子性 -> **磁盘 I/O 原子性**。Page 16KB。**Page 的原子性**?
******_ buffer pool 写入硬盘前写到这里
******_ 在故障恢复中可以在这里找到一份 page 的好的 copy
******_ 虽然数据写入两次(doublewrite buffer + page),但是写到 dw 是大块写入,一次 fsync()
***** Redo Log
******_ 故障恢复中修正未完成的事务的数据
******_ SQL 语句或低级 API 调用产生的更改表数据的请求进行编码
******_ ib_logfile0 & ib_logfile1
***** Undo Log
******_ 与单个读写事务相关联的撤消日志记录的集合
******_ 包含有关如何撤消事务对聚集索引记录的最新更改的信息
** ACID
*** Atomicity 中止(abort)
****_ 能够在错误时中止事务,丢弃该事务进行的所有写入变更的能力
****_ 事物
*** Consistency 不变量(invariants)
****_ doublewrite buffer
*** Isolation
****_ 锁
**** 事物隔离级别
' *****_ 读已提交(Read Committed)
*** Durability
****_ doublewrite buffer
****_ 运维
** 隔离级别
***_ READ UNCOMMITTED
*** READ COMMITTED
****_ 在同个事务中的每个一致性读设置及读其自己的新鲜的 snapshot
****_ lock r & u & d: 只锁索引记录而没有前面的 gap,可以任意插入记录
*** REPEATABLE READ
****_ 同个事物的**一致性读**读取第一个读建立的 snapshot
**** locking read & update & delete
*****_ 查询使用唯一索引只锁找到的 index record
*****_ 其他情况锁扫描到的索引范围
***_ SERIALIZABLE
** MVCC
*** 每行数据的隐藏字段
****_ DB_TRX_ID:最后插入或更新行的最新事务的标识
****_ DB_ROLL_PTR:指向写入 rollback segment 中的 undo log record
****_ DB_ROW_ID:当新行插入后单调递增的 row id
** 幻读
** 锁
*** Shared and Exclusive Locks
****_ Shared:允许事务持有锁读行
****_ Exclusive:允许事务持有锁更新或删除行
***:
Intention Locks:允许多粒度锁(行锁,表锁共存)。
表级锁表示事务将要对表中的某行请求什么类型的锁
;
*** Record Locks:在 **index record** 上的锁。即使没有索引,也会创建隐藏聚簇索引。
*** Gap Locks:锁 index records 的间隙。
****_ 使用唯一索引查找唯一行的语句不需要,直接锁行;
****_ 如果列没有索引或唯一索引,锁前面的间隙。
***_ Next-Key Locks:Record Lock + Gap Lock(index record 前的间隙)
***_ Insert Intention Locks:插入数据时设置的 gap lock
***_ AUTO-INC Locks
** explain
***_ id
*** select_type
****_ **SIMPLE**: 无 union 或 子查询
****_ **PRIMARY**: 最外
****_ **SUBQUERY**: 子查询中第一个 SELECT
****_ **DERIVED**
****_ **MATERIALIZED**
*** type
*** Extra
***_ possible_keys
***_ key
***_ key_len: 使用的 key 的长度
***_ rows
***_ filterd
***_ extra
** 索引
*** 种类
****_ 聚簇索引
****_ 二级索引
****_ 覆盖索引
***_ 自动生成的主键有什么问题
***_ 什么情况索引失效
** 运维
***_ 一张大表怎么更改表的数据结构,字段
*** [[https://segmentfault.com/a/1190000023810042 自增id用完了怎么办]]
****_ **自增主键**,主键冲突,id 仍为最大值
****_ 指定 row_id(6 byte) 为主键(共享),取 0
@endmindmap
@startmindmap explain type 脑图
* explain type
**_ **system**: 表只有一行
**_ **const**: 最多一行匹配;主键或者唯一键
**_:
**eq_ref**: 对于前面的
表中各种组合,此表只取出一行
;
**_:
**ref**: 对于前面的表的各种组合,
此表匹配的索引值
;
**_ **ref_or_null**: 像 ref 但再搜索 NULL 值
**_:
**index_merge**: key 中反映的是索引
使用的 key 的列表。
一张表的多个 range 扫描合并成一个
合并可能是交集、并集、差集
;
**_ **unique_subquery**: in 中的 eq_ref
**_:
**index_subquery**: 类似 unique_subquery
但不是在 unique 索引上
;
**_ **range**: 指定区间中的行被拉取
**_:
**index**: 连接类型同 all,只是索引树被扫描
覆盖索引满足查询的数据,Extra: Using index,比 all 快,索引数据小
按照索引顺序进行全表查询,Extra 中没有
;
**_ **ALL**: 对先前表中的每个行组合进行全表扫描。非常不好,加索引
@endmindmap
@startmindmap explain extra 脑图
* explain extra
**_ **backward index scan**: 使用 descending index(降序索引)
**_ **Distinct**: 找到第一个符合的行后就不再找
**_:
**FirstMatch(tbl_name)** 半连接找到第一个
半连接是一个子查询,它主要用于去重。只返回存在内表中的外表的记录,
EXSIT和IN语句组成的布尔表达式
;
**_:
**Using filesort** MySQL 必须执行额外的检查以找出如何按排序顺序检索行
找不到合适的索引来 order by。读表行来排序,如果临时结果集太大使用临时硬盘空间。
;
**_ **Using index**: 使用覆盖索引,不回表。也可以 type: index & key: primary
**_:
**Using index condition**: 索引条件下推,减少读全表行的可能性。
没有 ICP: base table 遍历 index 来找行,交给 存储引擎,其在 WHERE。
有 ICP: where 中部分列能通过 index 满足,存储引擎
;
**_:
**Using temporary**: 需要创建临时表保留结果
一般是 group by 和 order by 不同的字段
;
**_:
**Using where** 限制了哪些行匹配到下张表或者传给客户端。
如果 join type: [all | index], 而没有此项,就全表了,有问题。
;
@endmindmap
Redis
@startmindmap
* Redis
** 数据结构
*** Hash
**** 数据结构
*****_ ziplist
*****_:
哈希表
typedef struct dictht {
// 哈希表数组
dictEntry **table
// 哈希表大小
unsigned long size
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask
// 该哈希表已有节点的数量
unsigned long used
} dictht
;
*****_:
哈希表节点
typedef struct dictEntry {
// 键
void *key
// 值
union {
void *val
uint64_t u64
int64_t s64
} v
// 指向下个哈希表节点,形成链表
struct dictEntry *next
} dictEntry
;
*****_:
字典
typedef struct dict {
// 类型特定函数
dictType *type
// 私有数据
void *privdata
// 哈希表 ht[1]只在 rehash 使用
dictht ht[2]
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict
;
**** 负载因子
*****_ 没有 BG ht[0].used / ht[0].size > 1
*****_ 有 BG ht[0].used / ht[0].size > 5
*****_ BG 会启动子进程,copy-on-write,提高效率,提高负载因子,避免 re
*****_ ht[0].used / ht[0].size < 0.1 收缩
**** rehash
*****_ 1. 为 ht[1] 分配空间, 让字典同时持有 ht[0] 和 ht[1] 两个哈希表
*****_ 2. rehashidx = 0,表示开始
*****_ 3. 开始对桶内元素 rehash,完成后 hashidx++,表示下个桶位置
*****_ 4. ht[0] 所有的 rehash 完,hashidx = -1
*** Set
****_ 无序的 string 集合
**** 数据结构
*****_:
typedef struct **intset** {
// 保存元素所使用的类型的长度
uint32_t encoding
// 元素个数
uint32_t length
// 保存元素的数组
int8_t contents[]
} intset
;
*****_ hashset
*** Sorted Set
****_ skiplist
****_ ziplist
****_ 用途
*** String
****_ int
****_ long
****_:
raw(embstr < 39b **SDS**)
struct **sdshdr** { // 字符串长度
int len // buf数组中未使用的字节数
int free // 字节数组,用于保存字符串
char buf[]
}
;
**** 特点
*****_ 常数复杂度获取字符串长度,内置了长度
*****_ 杜绝缓冲区溢出,空间分配测测策略
*****_:
减少修改字符串时带来的内存重分配次数
< 1Mb --> *2
>= 1Mb --> +1Mb
free 记录未使用的空间,需要时删除
;
*****_ 二进制安全
*****_ 最大 512Mb
*** hyperloglog
**** 优缺点
*****_ 概率数据结构统计唯一的事物
*****_ < 1% 的误差
*****_ 最多用 12k
*****_ 技术上是不同的数据结构,但是编码成 string
*** List
**** 数据结构
*****_: **节点**
typedef structlis tNode{
struct listNode* prev // 前置节点
struct listNode* next // 后置节点
void* value // 节点值 可放任何节点
} listNode
;
*****_: **链表**
typedef struct list {
listNode *head // 表头节点
listNode *tail // 表尾节点
unsigned long len // 链表包含的节点数量
void* (*dup)(void* ptr) // 节点复制函数
void (*free)(void* ptr) // 节点释放函数
int (*match)(void* ptr, void* key) // 节点对比函数
} list
;
*****_ ziplist 节约内存
**** 使用场景
*****_ 社交网络最后更新的 post
*****_ 进程间交互生产者-消费者
**** 特点
*****_ 上限 list,LTRIM
*****_ 阻塞操作 B{L|R}{PUSH|POP}
*****_ 循环列表,可靠队列 LMOVE
*** bitmap
****_ 数据结构并不真实存在,string
****_ 最大 512M, 2^32
**** 用途
*****_ 各种实时分析
*****_ 存储与对象 id 相关的空间高效的高性能的 bool 信息
** 集群
*** cluster
****_ 16384 slot?
**** 原理
*** sentinel
****_ 选举过程
****_ 脑裂
****_ raft?
***_ 如何扩容
***_ 各个节点间怎么通信的
** 可用性
*** 与数据库一致性 *
****_ cache aside
****_ write through
***_ 缓存雪崩 多 key 集体失效
***_ 缓存击穿 单热点 key 失效
***_ 缓存穿透,猛攻 key 不存在,布隆过滤器
***_ 怎么保证redis和mysql的一致性
** [[https://mp.weixin.qq.com/s/JHeZr-sX1MdGdB8eWU95MQ Redis分布式锁无死角分析]] 分布式锁
***_ 实现方法
***_ 过期时间的制定
***_ 续锁
***_ RedLock
** [[https://zhuanlan.zhihu.com/p/356059845 多线程揭秘]]线程模型
*** 单线程的优缺点
**** 优点
*****_ I/O 密集型,非 CPU 密集型,瓶颈在于网络 I/O
*****_ 避免过多的上下文切换开销
*****_ 避免同步机制的开销
*****_ 简单可维护
**** 缺点
*****_:
多核的利用率并不算高,而且每次主线程都必须在分配完任务之后
忙轮询等待所有 I/O 线程完成任务之后才能继续执行其他逻辑
;
***_ 什么情况下会出现阻塞,怎么解决
** 持久化
*** AOF
**** 优点
*****_ durable 更高,fsync 策略不同
*****_ append only,不会出太多问题
*****_:
当 AOF 文件太大,自动后台重写。
Redis 继续写入旧文件。生成的文件足够小保留当前数据库。
第二个文件 ready,切换过去,开始写入新文件
;
*****_ 以简单和易懂的方式存一个接一个的操作
**** 缺点
*****_ 更大
*****_ 有不可重新的 BUG
****_ 命令的实时写入
**** 对 AOF 文件的重写
*****_ BGREWRITEAOF
*****_ 在不影响服务客户端的情况下重建日志
****_ 阻塞?
****_ 什么时候使用
**** durable
*****_ appendfsync always: 新命令添加到 AOF 执行,非常慢
*****_ appendfsync everysec: 每秒一次,默认及推荐
*****_ appendfsync no: 不 fsync
*** RDB
**** 优点
*****_ 紧凑的时间点的 Redis 数据。每小时保存最后 24 小时的数据,每 30 天一次快照
*****_ 利于灾难恢复,单一的紧凑文件
*****_ 最大化性能,因为父进程只是 fork 子进程
*****_ 重启相对较快
**** 缺点
*****_ 不适用最小化数据丢失
*****_ 如果数据库太大 fork() 耗时,ms ~ 1s
**** rdbSave
*****_ SAVE: 直接调用 rdbSave,阻塞;
*****_ BGSAVE: fork 子进程,子进程调用 rdbSave,仍处理请求
****_ rdbLoad
****_ 用处
****_ 什么时候使用
** 管道
***_ 用处
***_ 原理
***_ 原子性: 不保证
***_ 和事务的区别?
@endmindmap
ES
@startmindmap
* ES
** 原理
***_ 写入,查询过程
***_ 底层实现
** 集群
*** 脑裂问题
***_ 怎么产生的
***_ 如何解决
** 深度分页及优化
@endmindmap
分布式
@startmindmap
* 原理
** 一致性hash原理
***_ 解决的问题
***_ 数据倾斜
***_ 2^32 ?
** CAP
** BASE
** 幂等
** 康威定律
@endmindmap
Linux
@startmindmap
* Linux
** Kernel
***_ 用户态
***_ 内核态
***_ 有几种转换的方式,怎么转换的,转换失败怎么办
** 虚拟内存
***_ 虚拟地址和物理地址怎么转换
***_ 内存分段,内存分页,优缺点
** 进程
***_ fork函数,父子进程的区别
***_ 孤儿进程,僵尸进程会有什么问题
***_ 进程有哪些状态
***_ 进程间怎么同步,通信
***_ 消息队列,管道怎么实现的
***_ 进程调度算法
** 锁
***_ 自旋锁
***_ 线程上下文切换的开销具体
** 中断
@endmindmap
网络
@startmindmap
* Network
** 连接
***_ 用于保证可靠性和流控制机制的信息,包括 Socket、序列号以及窗口大小叫做连接。
***_ 最多建立多少个连接?[[https://www.zhihu.com/question/361111920/answer/1199952447 65535?]] *
*** 需要达成的共识
****_ 一对 Socket(IP + Port)
****_ 窗口大小(流控制)
****_ 序列号(追踪通信**发起方**发送的数据包序号,**接收方**确认成功接收)
** tcp/udp
*** [[https://draveness.me/whys-the-design-tcp-three-way-handshake/ tcp 三次握手]]
**** 流程
*****_ C --> S: SYN=1, seq=x
*****_ S --> C: SYN=1, ACK=1, seq=y, ACKnum=x+1
*****_ C --> S: ACK=1,ACKnum=y+1
**** 原因
*****_ 阻止历史的重复连接初始化造成的混乱问题,防止使用 TCP 协议通信的双方建立了错误的连接。
*****_ 初始序列号
*** [[https://draveness.me/whys-the-design-tcp-three-way-handshake/ tcp 四次挥手]]
**** 流程:客户端发起关闭
*****_ C -> S: FIN。 C 进入 FIN_WAIT_1
*****_ S -> C: ACK。 S 进入 CLOSE_WAIT
*****_ S -> C: FIN。 当 S 没有待发数据
*****_ C -> S: ACK。 C 进入 TIME_WAIT 后发送。S 接收 ACK 后进入 CLOSED
*****_ C 等 2 * MSL 后进入 CLOSED
**** time_wait
***** 原因
******_ 防止**延迟的数据段**被连接(一对 Socket)接到
******_ 保证 TCP 链接的远程被正确关闭
*** TCP Fast Open
****_ C -> S: SYN + TFO
****_ S -> C: ACK + Cookie。
****_ C 缓存 Cookie。 C -> S: Cookie + TFO
****_ S 验证 Cookie。 S -> C: SYN + ACK
****_ S -> C: Payload
***_ tcp、udp 区别
*** 报文结构
**** UDP
*****_ 源端口
*****_ 目的端口
*****_ 长度
*****_ 校验码
*** TCP 粘包
**** TCP 特性
*****_ 面向连接的、可靠的、**基于字节流**(没有<s>消息 & 数据包</s>)的传输层通信协议
*****_ <s>以消息为单位向目的主机传输</s>,数据组合成一个数据段发送给目标的主机
***** Nagle
******_ 小的数据块在本地缓冲区中等待更多待发送的数据
******_ 数据写入 TCP 缓冲区,待缓冲区 > MSS 或者上一个数据被 ACK 发送
******_ 用于:Telnet
******_ TCP_NODELAY = 1 关闭
******_ 优点:数据包较小时提高网络带宽的利用率并减少 TCP 和 IP 协议头带来的额外开销
******_ 缺点:应用层协议多次写入的数据被合并或者拆分发送
**** 解决:自己设计消息的边界(消息帧)
*****_ 长度: HTTP Content-Length
*****_ 终结符: HTTP Chunked 中负载大小为 0 作为边界
*** tcp 四次挥手
**** [[https://draveness.me/whys-the-design-tcp-time-wait 为什么 TCP 协议有 TIME_WAIT 状态]]
*****_ 防止延迟的数据段被其他使用相同源地址、源端口、目的地址以及目的端口的 TCP 连接收到
***** 保证 TCP 连接的远程被正确关闭
******_ 等待被动关闭连接的一方收到 FIN 对应的 ACK 消息
******_:
服务端没收到 ACK,客户端重新与服务端
建立连接,认为连接合法,握手会收到 RST;
***** 调优
******_:
SO_LINGER 设置暂存时间 l_linger 为 0,
关闭 TCP 连接,内核就会直接丢弃
缓冲区中的全部数据并向服务端
发送 RST 消息直接终止当前的连接;
******_:
<s>net.ipv4.tcp_tw_reuse TCP 的时间戳选项</s>
<s>允许内核重用处于 TIME_WAIT 状态的 TCP 连接</s>
;
*** TCP 拆分数据
**** TCP(Segment) 传输性能
*****_ 不会以<s>消息为单位向目的主机发送</s>
*****_ MSS(Max segment size) 正常: MTU - 40;默认 536 Byte
*****_ MSS 确定的是内核层面
**** IP(Packet) 物理设备限制
*****_ IP 提供路由和寻址
*****_ 不同设置间传输确定 MTU(Max transmission unit)
*** TCP 性能问题
**** 拥塞控制算法会在丢包时主动降低吞吐量
*****_ 线増积减(Additive increase/multiplicative decrease,AIMD)
***** 维护一个拥塞控制窗口(Congestion Window)
******_ 决定了发送方同时能向接收方发送多少数据
******_ 防止发送方向接收方<s>发送了太多数据</s>
******_ 防止 TCP 连接的任意一方向网络中<s>发送大量数据</s>
**** 三次握手增加了数据传输的延迟和额外开销
***** 额外开销是 222 字节
******_ 以太网数据帧占 3 * 14 = 42 字节
******_ IP 数据帧占 3 * 20 = 60 字节
******_ TCP 数据帧约占 120 字节
**** 累计应答机制导致了数据段的传输
** http
*** 请求头
****_ **expire**: 包含日期/时间, 即在此时候之后,响应过期。
****_ **cache-control**: 实现缓存机制
*** 状态码
****_ **1xx** 信息响应
****_ **3xx** 重定向
****_ **301 Moved Permanently** 永久重定向到由 Location 头部指定的url上
****_ **302 Found** 暂时的移动到了由Location 头部指定的 URL 上
****_ **401 Unauthorized** 由于缺乏目标资源要求的身份验证凭证
****_ **403 Forbidden** 服务器端有能力处理该请求,但是拒绝授权访问
** https
***_ 原理
***_ 数字签名
***_ 数字证书
***_ 非对称加密算法
@endmindmap
TCP 最多可建立多少个连接?
fs.file-max: 当前系统可打开的最大数量
fs.nr_open: 当前系统单个进程可打开的最大数量
nofile: 每个用户的进程可打开的最大数量
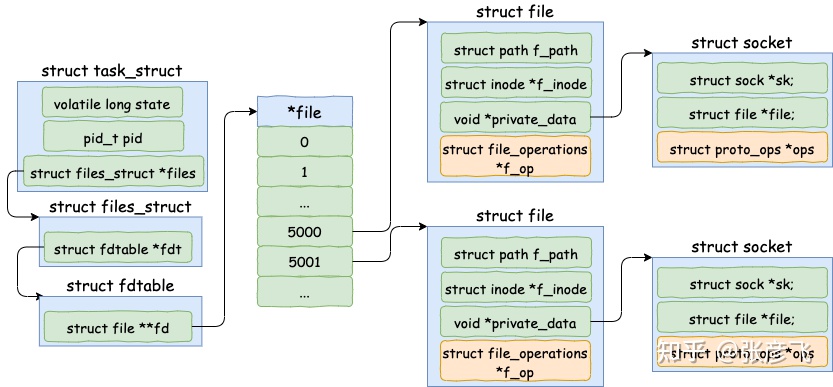
linux 下一切皆文件,包括 socket。所以每当进程打开一个 socket 时候,内核实际上都会创建包括 file 在内的几个内核对象。该进程如果打开了两个 socket,那么它的内核对象结构如下图。
Spring
@startmindmap
* Spring
** Framework
*** 循环依赖
****_ 怎么解决
****_ 为何三级缓存?
*** 生命周期
*** bean创建过程
*** 事务失效及原因
*** 怎么加载类
*** @Component & @Bean 的区别
****_ @Component class 没有 CGLIB,@Bean + @Configuration 有 CGLIB,有完整的 Spring lifecycle
****_ @Component 作用于类,@Bean 作用于方法
*** 用到了哪些设计模式
@endmindmap